
 4 hours ago
5
4 hours ago
5

PCI Express (PCIe) is a foundational technology that's been around for decades, and that's not going to change anytime soon. The standard is set to change and evolve over the coming years, and the technology has a rich history behind it, too. PCIe inherited elements from the original PCI standard (such as configuration space, PnP, BARs, and command/status registers), so the history of this technology stretches into the annals of computing history.
Ever since its introduction in 2004, PCIe has been evolving in accordance with a simple rule: each new major revision roughly doubles link bandwidth while maintaining backward compatibility. The pace of formally introducing a new PCIe version every three or four years remained mostly stable, barring a major slip between PCIe 3.0 and PCIe 4.0. But what changed in recent years is not the pace, but the difficulty of each new iteration. Early generations increased throughput almost effortlessly by doubling transfer rates (clocks) and improving encoding efficiency. Today, the roadmap pushes PCIe directly into the territory where manufacturing tolerances, materials, and retimers define what is possible and how much it costs.
Article continues below
A quick look back
PCIe began as a replacement for shared buses in the early 2000s and introduced point-to-point connections and scalable lane counts. PCIe 1.0 operated at a 2.5 GT/s data transfer rate per lane, followed by PCIe 2.0 at 5 GT/s. PCIe 3.0 increased the data rate to 8 GT/s, which was far from doubling the prior generation, but introduced a more efficient 128b/130b NRZ encoding scheme, which significantly reduced protocol overhead.
PCIe 4.0 doubled the transfer rate to 16 GT/s in 2017, and marked the first time where a new PCIe revision was adopted by enthusiast-grade desktop PCs only two years after the formal publication of the standard.
Swipe to scroll horizontally
PCIe 7.0 (2025) | 128.0 GT/s | 1b/1b (Flit Mode*) | PAM4 |
PCIe 6.0 (2022) | 64.0 GT/s | 1b/1b (Flit Mode*) | PAM4 |
PCIe 5.0 (2019) | 32.0 GT/s | 128b/130b | NRZ |
PCIe 4.0 (2017) | 16.0 GT/s | 128b/130b | NRZ |
PCIe 3.0 (2010) | 8.0 GT/s | 128b/130b | NRZ |
PCIe 2.0 (2007) | 5.0 GT/s | 8b/10b | NRZ |
PCIe 1.0 (2003) | 2.5 GT/s | 8b/10b | NRZ |
PCIe 5.0 followed in 2019 at 32 GT/s per lane, and brought the electrical designs of data centers to client systems, requiring higher-grade PCB materials and stricter signal-integrity controls. Now, the bus provides up to 128 GB/s bidirectional bandwidth through an x16 slot, which is an overkill for consumer graphics cards, but increasingly useful for AI accelerators and high-end storage.
While PCIe 5.0 connectivity is must have for data centers, not every mainstream and entry-level consumer PC supports PCIe 5.0 for SSDs and graphics cards, which highlights that the cost of the technology introduced in 2019 is still fairly high for inexpensive computers.
PCIe 6.0: An inflection point
Introduced in 2022, PCIe 6.0 represented a major inflection point for the technology: instead of driving conventional two-level signaling to ever higher frequencies, the specification transitioned to PAM4, a four-level modulation method that carries two bits per symbol, and introduced 242B/256B FLIT encoding. This change allows throughput to double to 64 GT/s per lane without doubling the clock rate, but it comes with severe tradeoffs.
Multi-level signaling methods like PAM4 compress voltage margins dramatically, making them far more sensitive to electrical noise, jitter, crosstalk between lanes, and even tiny imperfections in PCB manufacturing, something that historically reserved this transmission method in enterprise-grade networking like 400Gb Ethernet or InfiniBand.
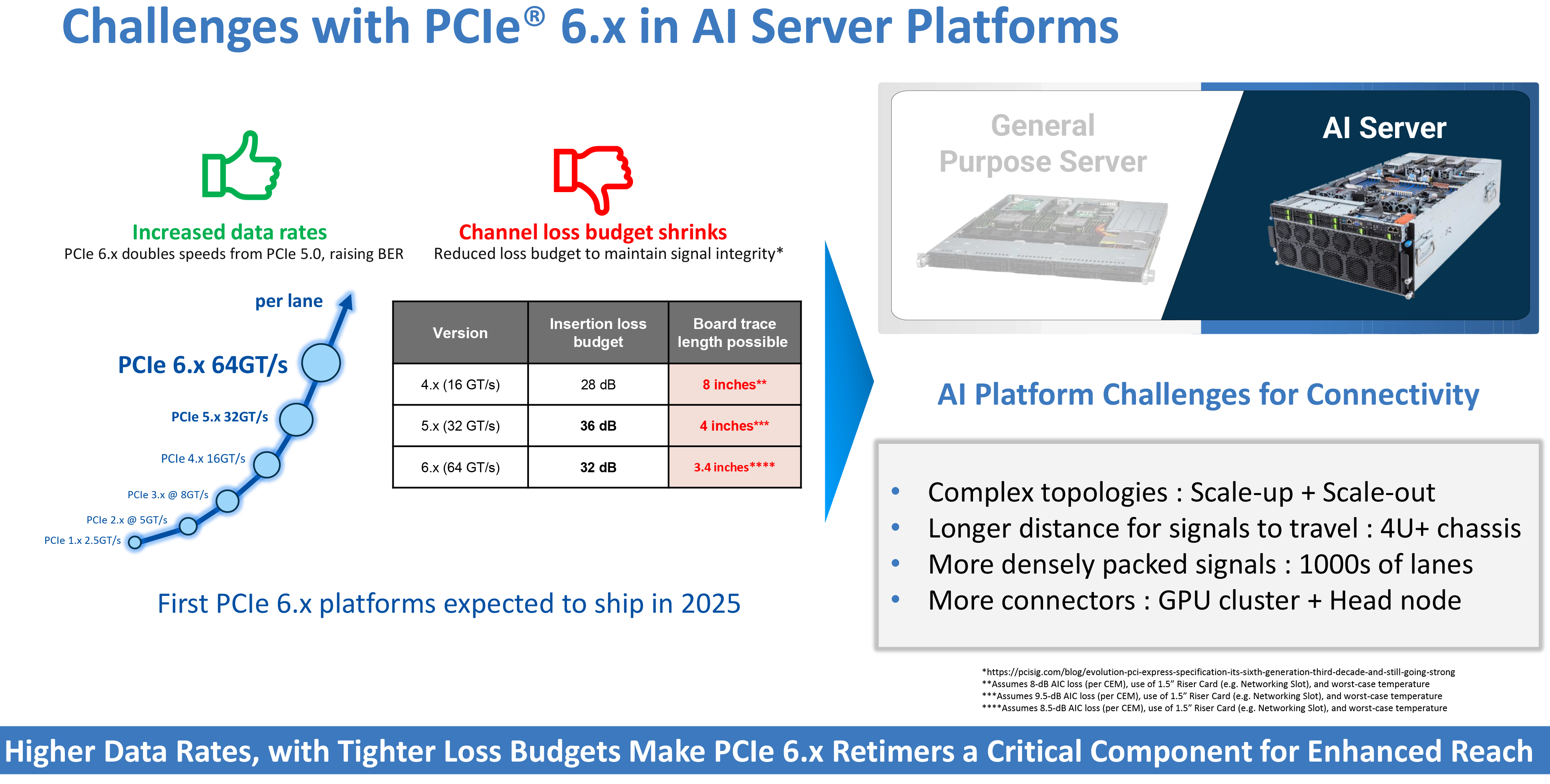
To ensure that everything works, PCI-SIG mandated forward error correction (FEC) and significantly more complex equalization, which is costly in terms of silicon complexity (more compute power required), added latency, and power.
To a large degree, PCIe 6.0 controllers with Physical Interfaces (PHYs) now resemble mixed-signal processors, rather than simple interfaces, as they now have to pack DSP blocks for high-resolution analog processing, adaptive equalization, and FEC engines, which all consume power. Furthermore, validation requirements across the platform are much tighter with PCIe 6.0 compared to previous generations.
Meanwhile, from a platform perspective, the greatest limitation is no longer bandwidth or latency; it is distance. At PCIe 4.0's 16 GT/s and PCIe 5.0's 32 GT/s, system designers can still route signals across motherboard traces up to 11 inches under favorable conditions using quality materials. This is no longer the case with PCIe 6.0. According to channel-loss figures published by Astera Labs, a direct copper trace operating at 64 GT/s can span as little as 3.4 inches under a 32 dB loss budget, depending on materials and conditions.

To a large degree, such constraints redefine motherboard engineering: lengths once considered trivial now require architectural decisions, since factors like dielectric loss, copper surface roughness, via impedance, and connector discontinuities all affect signal integrity. Consumer-grade laminates have also become inadequate, mandating manufacturers to use high-cost, low-loss materials typically reserved for networking equipment.
Furthermore, since raw copper can no longer maintain usable eye graph margins across practical distances, retimers are no longer optional for meaningful distances between the root complex and the slot: modern servers with PCIe 5.0 use between 17 and 24 of them, and PCIe 6.0 is set to raise that dependency dramatically. For example, two retimers per link can extend a PCIe Gen6 trace reach to roughly 10 inches, but the PCIe specification does not allow more than two retimers between a host and an endpoint, so server motherboard designers must be creative.
Retimers are not a panacea, though: each retimer adds unavoidable latency, cost, validation burden, and power draw, easily adding over 200W per server. Connector design faces similar pressure. Interfaces originally designed for signaling in the low single-digit GHz range are now expected to operate cleanly at tens of GHz, which is why companies like Molex are introducing new connector and cable families explicitly for PCIe 6.0 and 7.0. Obviously, such connectors and cables are expensive, complex, and physically larger than they used to be in PCIe 4.0 times.
Given all the complexities surrounding PCIe 6.0, Wallace C. Kuo, chief executive of Silicon Motion, says that he does not expect consumer-grade SSDs with a PCIe 6.0 interface to become a widely-adopted product before 2030.
PCI 7.0, 8.0 and beyond
Beyond PCIe Gen 6, the roadmap remains consistent in terms of cadence and performance increase, but hardly in terms of implementation and adoption cadence by the industry. PCIe 7.0 targets another performance doubling to 128 GT/s per lane, but this time actually increasing clocks and further refining the PAM4 modulation scheme and tightening electrical tolerances.
Swipe to scroll horizontally
PCIe 1.x + | 2.5 | 500 MB/S | 1 GB/S | 2 GB/S | 4 GB/S | 8 GB/S |
PCIe 2.x + | 5 | 1 GB/S | 2 GB/S | 4 GB/S | 8 GB/S | 16 GB/S |
PCIe 3.x + | 8 | 2 GB/S | 4 GB/S | 8 GB/S | 16 GB/S | 32 GB/S |
PCIe 4.x + | 16 | 4 GB/S | 8 GB/S | 16 GB/S | 32 GB/S | 64 GB/S |
PCIe 5.x + | 32 | 8 GB/S | 16 GB/S | 32 GB/S | 64 GB/S | 128 GB/S |
PCIe 6.x + | 64 | 16 GB/S | 32 GB/S | 64 GB/S | 128 GB/S | 256 GB/S |
PCIe 7.x + | 128 | 32 GB/S | 64 GB/S | 128 GB/S | 256 GB/S | 512 GB/S |
PCIe 8.x + | 256 | 64 GB/S | 128 GB/S | 256 GB/S | 512 GB/S | 1 TB/S |
PCIe 8.0, which is still under development, aims to double that again to 256 GT/s with the specification available sometime in 2028. If achieved, an x16 connection would approach an almost 1 TB/s of aggregated bandwidth in both directions. Whether such speeds remain viable on copper is an open question. Connector vendors are already developing specialized hardware, including extended-reach cables and high-density sockets, to accommodate future data rates. Optical interconnects and co-packaged PHY designs are no longer academic exercises and could become requirements at some point, although Al Yanes, the head of PCI-SIG, implies that the organization is looking forward to enabling a 256 GT/s speed over copper. Only time will be able to tell if that'll become a reality.
The future of PCIe: Predictable performance, demanding silicon
One notable question about the evolution of PCI and PCIe technologies is what defines them at different parts of their history. Intel originally began developing PCI for desktop PCs in 1990, only envisioning its entrance in the server space in the mid-1990s. Yet, by the time PCIe entered the scene, Intel was dominating the server market early in the new millennium.
Both PCI and PCIe were originally designed with PCs in mind as PC sales grew at a high pace in the 1990s and early 2010s, driving sales of bandwidth-hungry graphics cards that were (and still are) mandatory for video games. Over the following years, the growth of cloud infrastructure flourished, demanding its own set of capabilities and costs. Today, AI infrastructure dominates, setting new targets for performance and capabilities.
In general, the PCIe roadmap still promises predictable performance growth. But given what application is now driving the IT world, maintaining that pattern now demands exponential increases in engineering effort. Higher data rates shorten trace distances, raise board costs, and require more active silicon to preserve signal integrity. But at the same time, make more work done at any given second, thus maximizing performance efficiency.
However, whether future generations remain electrical or transition toward optics, PCI Express is no longer optional; it is the structural backbone of modern compute systems, starting from a humble PC all the way to Elon Musk's Colossus with hundreds of thousands of Nvidia GPUs.








 English (US) ·
English (US) ·