
 1 day ago
18
1 day ago
18

A method devised by YouTuber, Googler, and security researcher LaurieWired could have huge implications for a very few specific use cases and workloads that are highly sensitive to "tail latency," or near-worst-case memory access latency. The project is called TailSlayer, and fundamentally, leverages hedging memory accesses to avoid running into DRAM refresh stalls.
Without getting fully into the weeds, the type of memory we all use, DRAM, has one serious downside: it has to be refreshed constantly. The cells where DRAM stores its data are fundamentally tiny capacitors, and they are highly leaky by design, so we have to continually top up the charge in them to make sure that they retain their data. This is known as DRAM Refresh. The refresh cycle happens at a rate that varies widely depending on the system and type of DRAM in question, but generally it's going to happen at an interval that is measured in microseconds, meaning that your memory is refreshing hundreds of times in the time it takes you to blink.
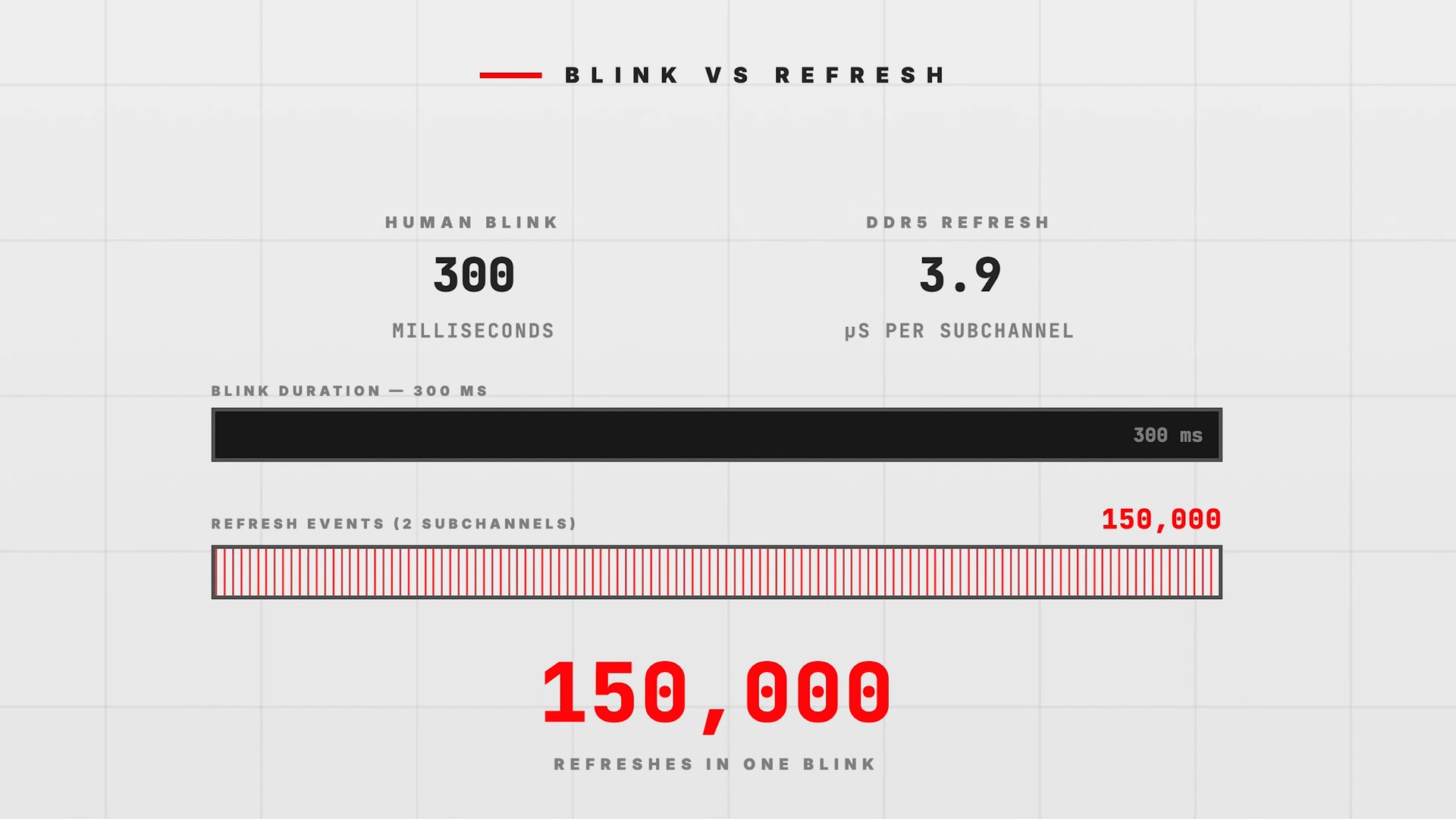
Now, DRAM refreshes aren't performed synchronously with memory accesses. Because of that, it's entirely possible that your system may try to access memory that's currently being refreshed. If that happens, the request simply stalls until the refresh cycle is finished. This can cause a stall of hundreds of nanoseconds, which isn't a long time in absolute terms, but at the speeds of modern chips, even a 200-nanosecond stall can be a thousand cycles where a CPU core isn't getting any work done.
Article continues below
This isn't a major problem for most use cases because we have all kinds of strategies in place to deal with stalls like this; this problem has been known since the 1960s when DRAM was invented, so naturally, hundreds of very smart people have put their genius to work developing workarounds. However, certain very specific workloads are extremely sensitive to non-deterministic memory latency, and these DRAM refresh cycle stalls are a major source of exactly that kind of behavior.
So what can you do? LaurieWired decided to tackle this problem for reasons she never fully elucidates but which probably boil down to "it was interesting," given her other work. Her initial ideas involve attempting to predict DRAM refreshes and synchronize around them, but that's completely impossible for several reasons she goes over in her video. Her next idea was parallelism, but she was stymied by CPU cache and reorder buffers—CPU features that largely obviate the issue in the first place.

Her breakthrough was when she realized she didn't necessarily have to do all of this on one CPU core. In the end, what she did was elect to fully duplicate the working set across memory addressing boundaries, ensuring that each copy resides on a different physical memory channel with independent timing behavior, and then run her operations simultaneously on two different CPU cores with each accessing a different memory channel. Then, she could simply let them race to finish and take the result of the one that finishes first; if one core hits a DRAM refresh interval, the likelihood that the other core also does is pretty low. This method allowed her to reduce the tail latency of DRAM accesses on her consumer Ryzen desktop system by more than half, which is huge.
By renting server time on Amazon AWS instances, she was able to test on high-end AMD, Intel, and Arm server hardware. She managed to achieve far greater results on these machines for a few reasons: they have slower CPU clock rates and slower memory, and they also have more conservative memory timings, that mean stalls are even worse for performance. The real difference is in the number of available memory channels, though. An EPYC Turin processor has some twelve memory channels, and by executing her strategy there, hedging across all twelve channels, she was able to cut near-worst-case memory latency (tail latency) by a staggering 89%.
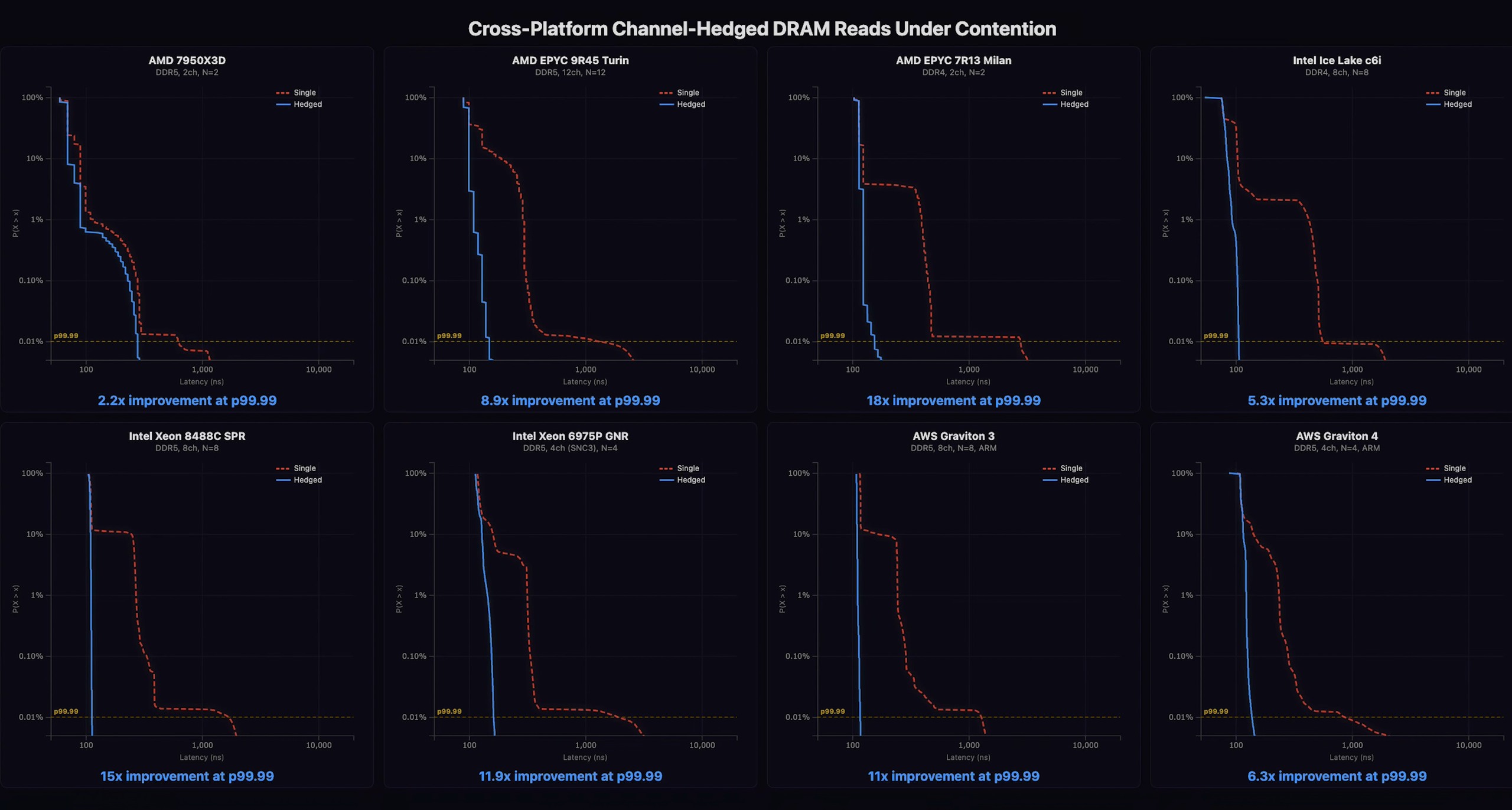
The clever hacker achieved even better results on Intel and Arm hardware. On Intel Xeon processors from the Sapphire Rapids and Diamond Rapids families, she managed to achieve gains as high as 93.3%, or in other words, she slashed p99.99 memory latency from 1697ns all the way down to 113ns. Considering the lowest value on the chart is around 105ns, that means the Xeon managed to achieve unbelievably deterministic memory latency.
I've said a few times that "certain workloads" benefit from TailSlayer. The most obvious place where determinism in memory latency is absolutely critical is in the slightly absurd world of high-frequency trading (HFT). If you're not familiar, imagine a bunch of hyper-caffeinated algorithms in a cage match where the winner is whoever can buy or sell a stock a few microseconds before everyone else. HFT firms spend obscene amounts of money on servers co-located right next to the exchange's matching engine, shaving off nanoseconds with custom hardware, microwave links instead of fiber optics, and code so obsessively optimized it would make a demoscene guru blush.
These systems operate with such tight tolerances that if a memory access runs into a DRAM refresh cycle, the opportunity is likely missed, potentially costing the firm millions of dollars. Because of that, the HFT world is the most obvious place where technology like this could be deployed, and it's almost one of the only places where it makes sense. There are other workloads that benefit from eliminating DRAM refresh stalls, sure; high-QPS microservices, matching engines, real-time ranking structures, anything using concurrent queues, and even potentially simulators or game servers, particularly those operating with a high level of precision.

The problem with using TailSlayer for many of these workloads will have already become apparent to many of you reading this, and it's primarily that Laurie's method requires fully duplicating the working set of the application for each memory channel you're hedging across. You're trading memory capacity and CPU cores for latency determinism, as this effectively multiplies memory requirements for any given application by a factor of the number of hedges you're willing to make. For some tasks—like, again, HFT—the actual memory requirements are quite modest, and so accepting a twelve-fold increase in memory usage in exchange for a 15× drop in p99.99 memory latency makes sense. For most workloads, it doesn't.
Your RAM Has a 60 Year Old Design Flaw. I Bypassed It. - YouTube

Of course, LaurieWired acknowledges this in her 54-minute video talking about the technique. In general, while she's (understandably!) quite pleased to have come up with TailSlayer, she's also quite frank about its relatively limited utility. Her video goes into significant depth about the research she had to do, including reverse-engineering undocumented memory scrambling behavior as well as devising a way to make the method work on Amazon's Graviton Arm-based CPUs, since they don't expose the same level of hardware counters that x86-64 CPUs do. It's highly recommended to watch if you're interested in the topic. Alternatively, you can head over to her GitHub repository to check out the demo code for yourself.

Follow Tom's Hardware on Google News, or add us as a preferred source, to get our latest news, analysis, & reviews in your feeds.








 English (US) ·
English (US) ·