
 1 day ago
2
1 day ago
2
Compute costs scale with the square of the input size. That's not great.
Credit: Aurich Lawson | Getty Images
Large language models represent text using tokens, each of which is a few characters. Short words are represented by a single token (like "the" or "it"), whereas larger words may be represented by several tokens (GPT-4o represents "indivisible" with "ind," "iv," and "isible").
When OpenAI released ChatGPT two years ago, it had a memory—known as a context window—of just 8,192 tokens. That works out to roughly 6,000 words of text. This meant that if you fed it more than about 15 pages of text, it would “forget” information from the beginning of its context. This limited the size and complexity of tasks ChatGPT could handle.
Today’s LLMs are far more capable:
- OpenAI’s GPT-4o can handle 128,000 tokens (about 200 pages of text).
- Anthropic’s Claude 3.5 Sonnet can accept 200,000 tokens (about 300 pages of text).
- Google’s Gemini 1.5 Pro allows 2 million tokens (about 2,000 pages of text).
Still, it’s going to take a lot more progress if we want AI systems with human-level cognitive abilities.
Many people envision a future where AI systems are able to do many—perhaps most—of the jobs performed by humans. Yet many human workers read and hear hundreds of millions of words during our working years—and we absorb even more information from sights, sounds, and smells in the world around us. To achieve human-level intelligence, AI systems will need the capacity to absorb similar quantities of information.
Right now the most popular way to build an LLM-based system to handle large amounts of information is called retrieval-augmented generation (RAG). These systems try to find documents relevant to a user’s query and then insert the most relevant documents into an LLM’s context window.
This sometimes works better than a conventional search engine, but today’s RAG systems leave a lot to be desired. They only produce good results if the system puts the most relevant documents into the LLM’s context. But the mechanism used to find those documents—often, searching in a vector database—is not very sophisticated. If the user asks a complicated or confusing question, there’s a good chance the RAG system will retrieve the wrong documents and the chatbot will return the wrong answer.
And RAG doesn’t enable an LLM to reason in more sophisticated ways over large numbers of documents:
- A lawyer might want an AI system to review and summarize hundreds of thousands of emails.
- An engineer might want an AI system to analyze thousands of hours of camera footage from a factory floor.
- A medical researcher might want an AI system to identify trends in tens of thousands of patient records.
Each of these tasks could easily require more than 2 million tokens of context. Moreover, we’re not going to want our AI systems to start with a clean slate after doing one of these jobs. We will want them to gain experience over time, just like human workers do.
Superhuman memory and stamina have long been key selling points for computers. We’re not going to want to give them up in the AI age. Yet today’s LLMs are distinctly subhuman in their ability to absorb and understand large quantities of information.
It’s true, of course, that LLMs absorb superhuman quantities of information at training time. The latest AI models have been trained on trillions of tokens—far more than any human will read or hear. But a lot of valuable information is proprietary, time-sensitive, or otherwise not available for training.
So we’re going to want AI models to read and remember far more than 2 million tokens at inference time. And that won’t be easy.
The key innovation behind transformer-based LLMs is attention, a mathematical operation that allows a model to “think about” previous tokens. (Check out our LLM explainer if you want a detailed explanation of how this works.) Before an LLM generates a new token, it performs an attention operation that compares the latest token to every previous token. This means that conventional LLMs get less and less efficient as the context grows.
Lots of people are working on ways to solve this problem—I’ll discuss some of them later in this article. But first I should explain how we ended up with such an unwieldy architecture.
The “brains” of personal computers are central processing units (CPUs). Traditionally, chipmakers made CPUs faster by increasing the frequency of the clock that acts as its heartbeat. But in the early 2000s, overheating forced chipmakers to mostly abandon this technique.
Chipmakers started making CPUs that could execute more than one instruction at a time. But they were held back by a programming paradigm that requires instructions to mostly be executed in order.
A new architecture was needed to take full advantage of Moore’s Law. Enter Nvidia.
In 1999, Nvidia started selling graphics processing units (GPUs) to speed up the rendering of three-dimensional games like Quake III Arena. The job of these PC add-on cards was to rapidly draw thousands of triangles that made up walls, weapons, monsters, and other objects in a game.
This is not a sequential programming task: triangles in different areas of the screen can be drawn in any order. So rather than having a single processor that executed instructions one at a time, Nvidia’s first GPU had a dozen specialized cores—effectively tiny CPUs—that worked in parallel to paint a scene.
Over time, Moore’s Law enabled Nvidia to make GPUs with tens, hundreds, and eventually thousands of computing cores. People started to realize that the massive parallel computing power of GPUs could be used for applications unrelated to video games.
In 2012, three University of Toronto computer scientists—Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton—used a pair of Nvidia GTX 580 GPUs to train a neural network for recognizing images. The massive computing power of those GPUs, which had 512 cores each, allowed them to train a network with a then-impressive 60 million parameters. They entered ImageNet, an academic competition to classify images into one of 1,000 categories, and set a new record for accuracy in image recognition.
Before long, researchers were applying similar techniques to a wide variety of domains, including natural language.
RNNs worked fairly well on short sentences, but they struggled with longer ones—to say nothing of paragraphs or longer passages. When reasoning about a long sentence, an RNN would sometimes “forget about” an important word early in the sentence. In 2014, computer scientists Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio discovered they could improve the performance of a recurrent neural network by adding an attention mechanism that allowed the network to “look back” at earlier words in a sentence.
In 2017, Google published “Attention Is All You Need,” one of the most important papers in the history of machine learning. Building on the work of Bahdanau and his colleagues, Google researchers dispensed with the RNN and its hidden states. Instead, Google’s model used an attention mechanism to scan previous words for relevant context.
This new architecture, which Google called the transformer, proved hugely consequential because it eliminated a serious bottleneck to scaling language models.
Here’s an animation illustrating why RNNs didn’t scale well:
This hypothetical RNN tries to predict the next word in a sentence, with the prediction shown in the top row of the diagram. This network has three layers, each represented by a rectangle. It is inherently linear: it has to complete its analysis of the first word, “How,” before passing the hidden state back to the bottom layer so the network can start to analyze the second word, “are.”
This constraint wasn’t a big deal when machine learning algorithms ran on CPUs. But when people started leveraging the parallel computing power of GPUs, the linear architecture of RNNs became a serious obstacle.
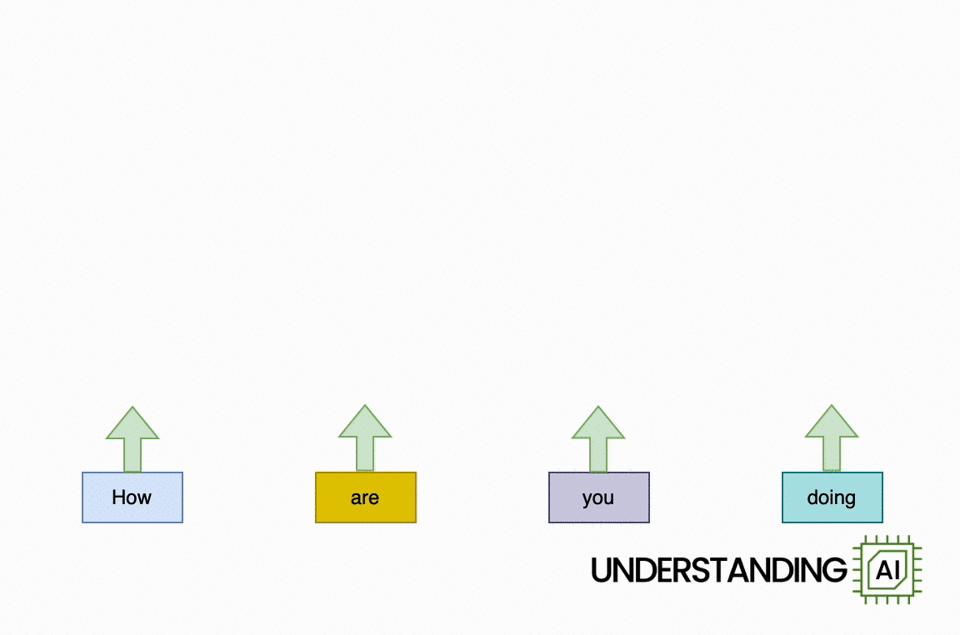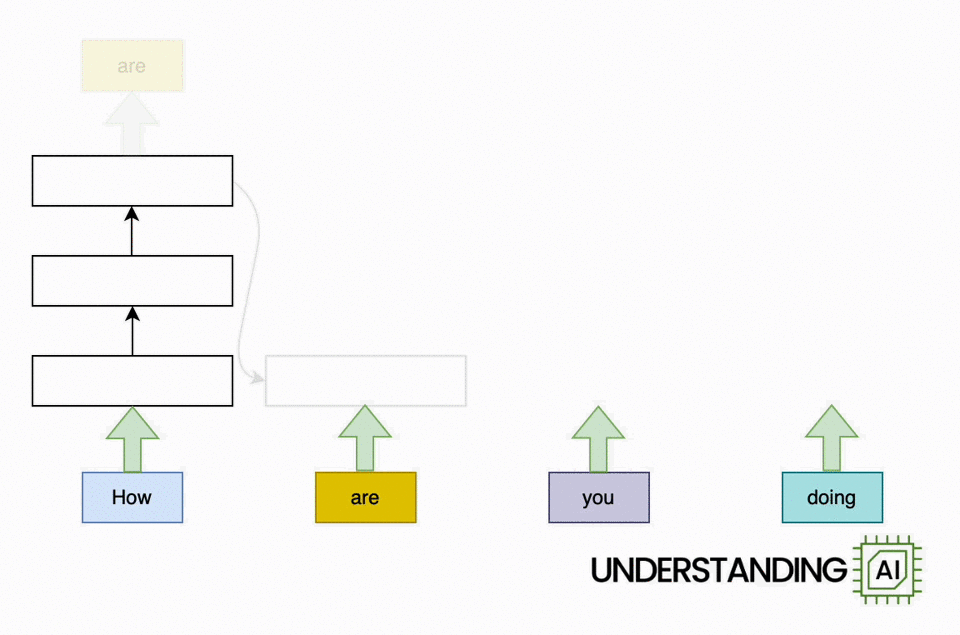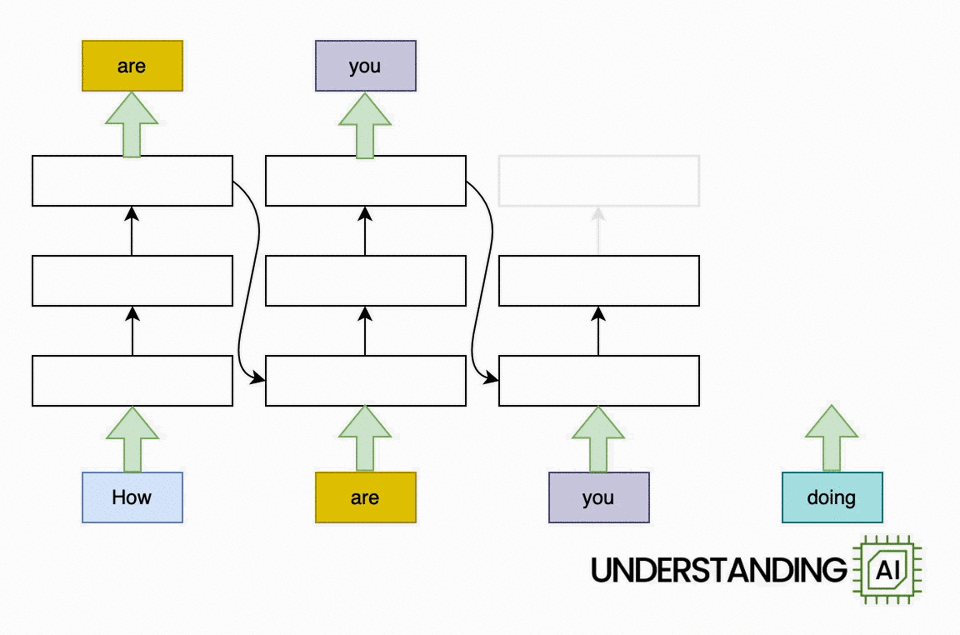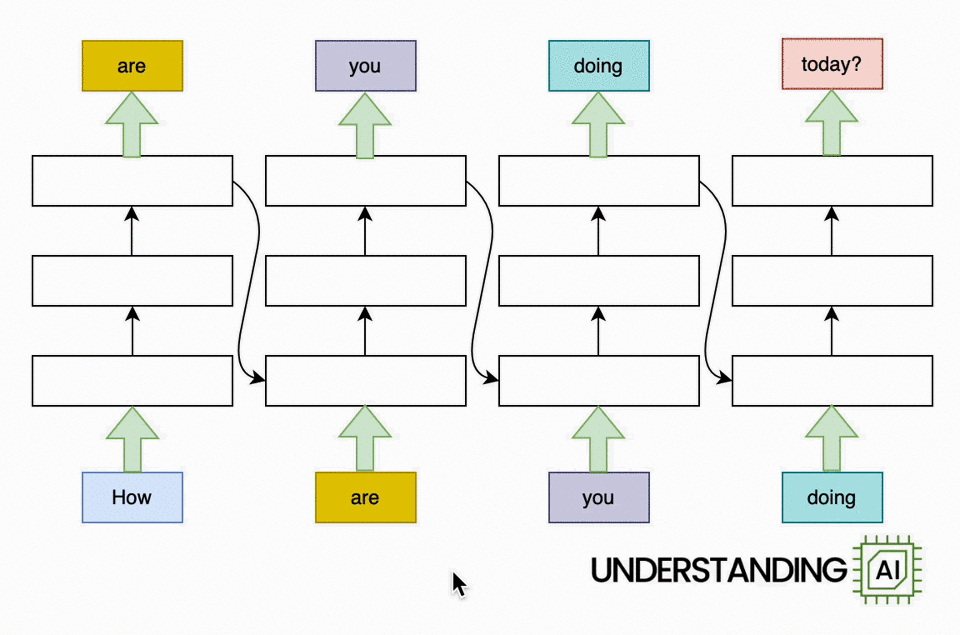
The transformer removed this bottleneck by allowing the network to “think about” all the words in its input at the same time:
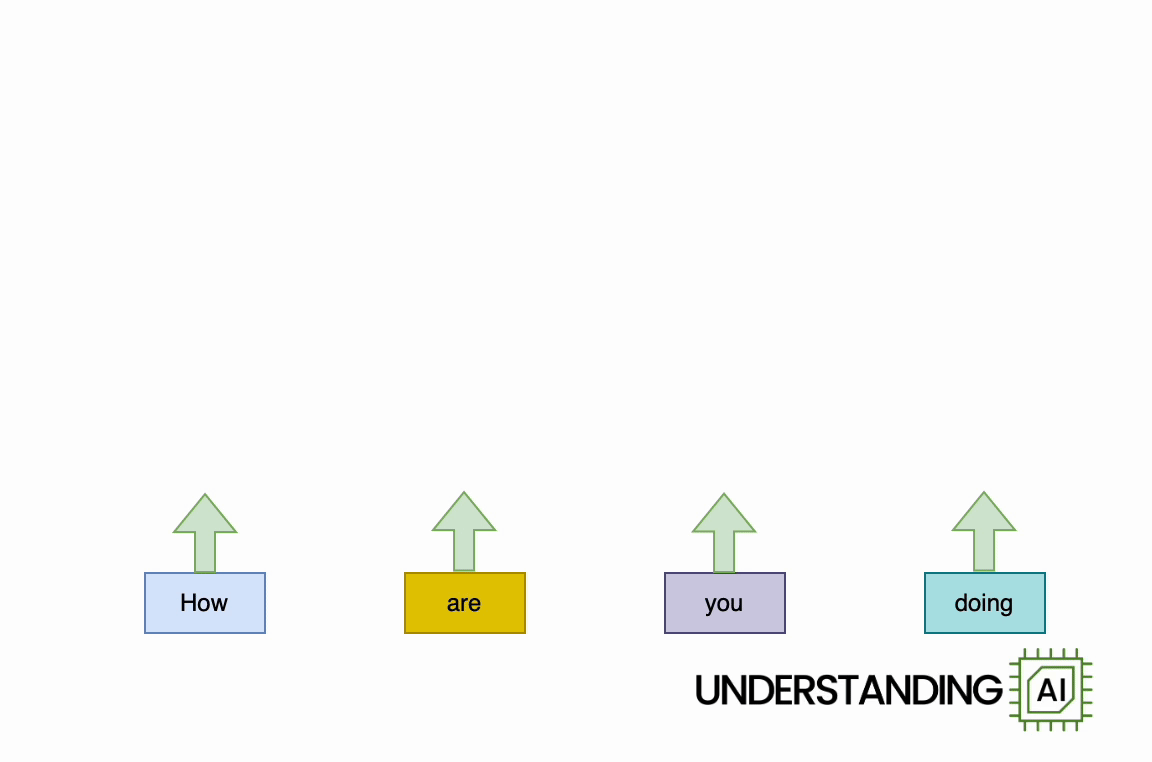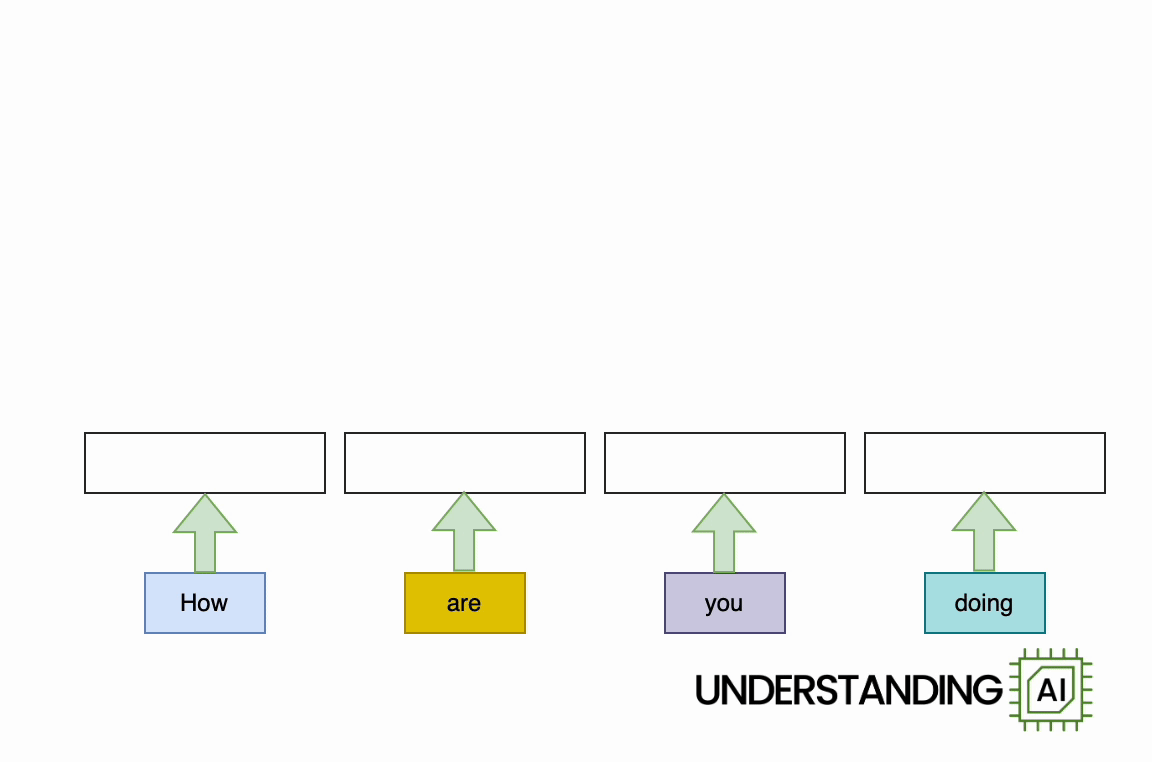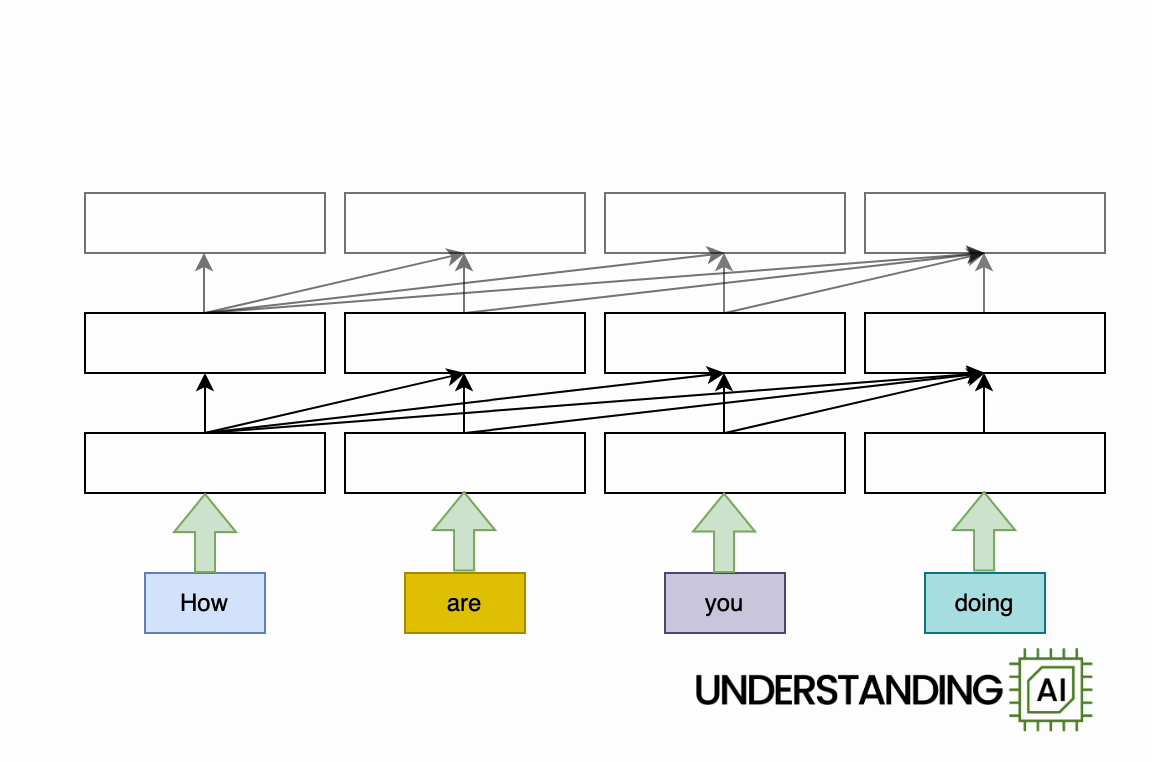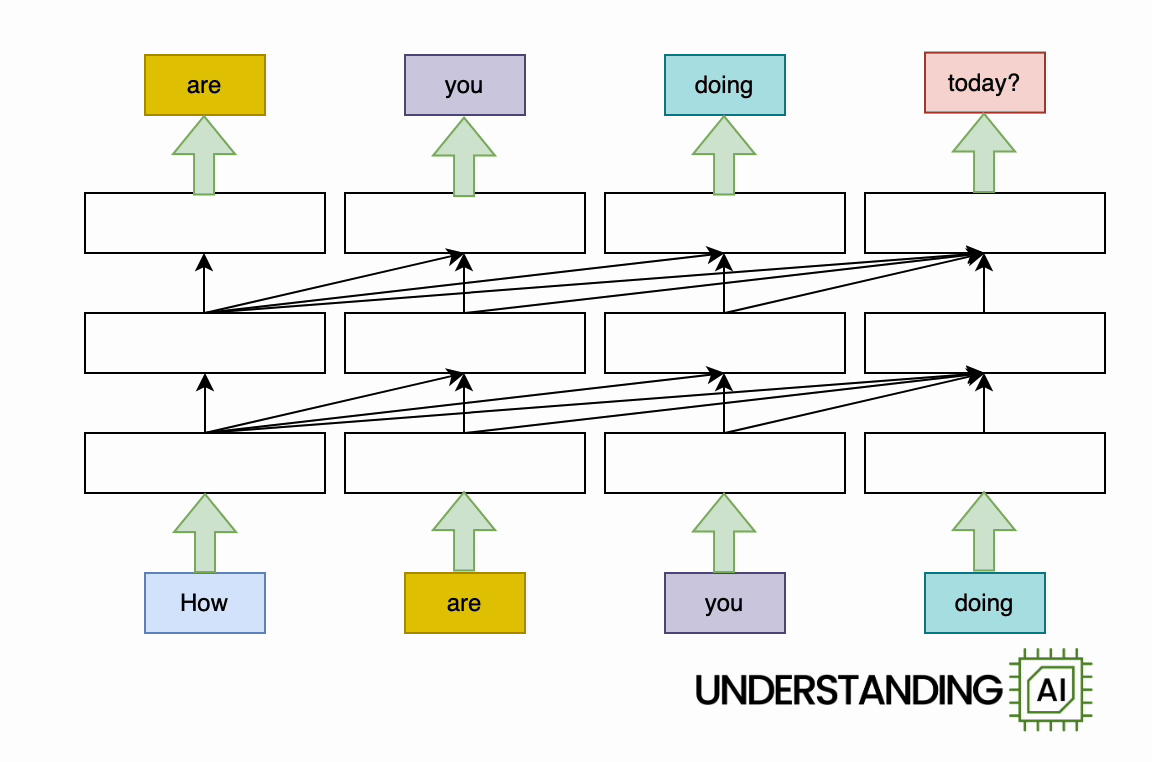
The transformer-based model shown here does roughly as many computations as the RNN in the previous diagram. So it might not run any faster on a (single-core) CPU. But because the model doesn’t need to finish with “How” before starting on “are,” “you,” or “doing,” it can work on all of these words simultaneously. So it can run a lot faster on a GPU with many parallel execution units.
How much faster? The potential speed-up is proportional to the number of input words. My animations depict a four-word input that makes the transformer model about four times faster than the RNN. Real LLMs can have inputs thousands of words long. So, with a sufficiently beefy GPU, transformer-based models can be orders of magnitude faster than otherwise similar RNNs.
In short, the transformer unlocked the full processing power of GPUs and catalyzed rapid increases in the scale of language models. Leading LLMs grew from hundreds of millions of parameters in 2018 to hundreds of billions of parameters by 2020. Classic RNN-based models could not have grown that large because their linear architecture prevented them from being trained efficiently on a GPU.
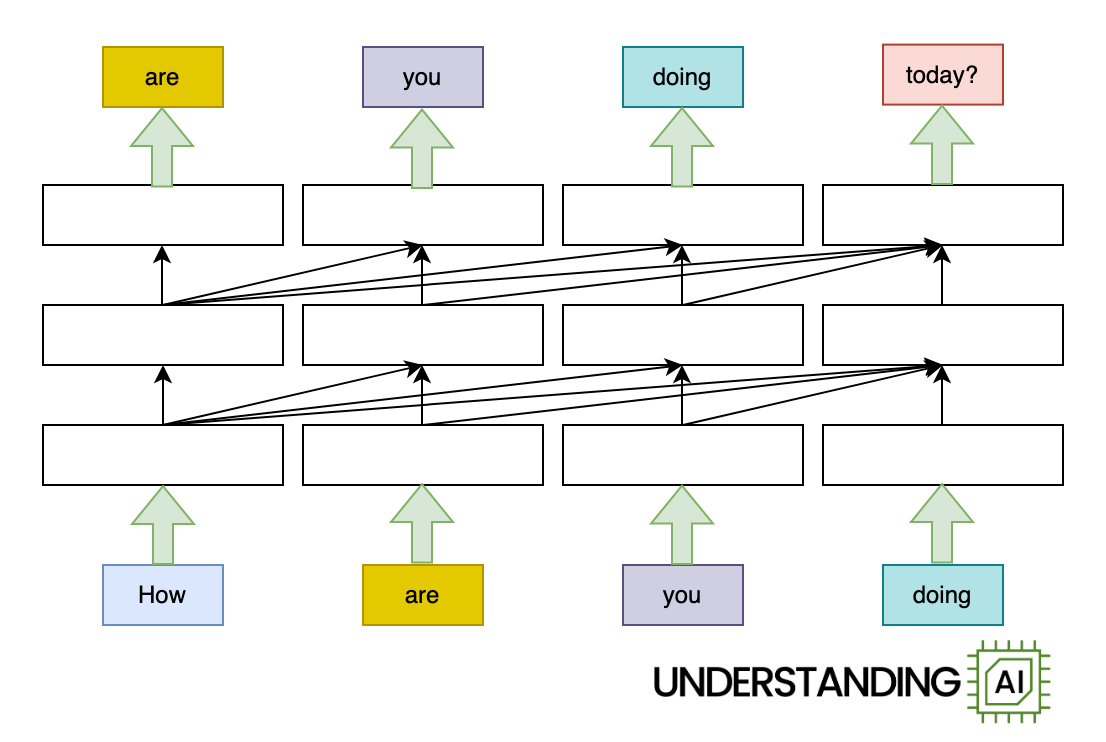
See all those diagonal arrows between the layers? They represent the operation of the attention mechanism. Before a transformer-based language model generates a new token, it “thinks about” every previous token to find the ones that are most relevant.
Each of these comparisons is cheap, computationally speaking. For small contexts—10, 100, or even 1,000 tokens—they are not a big deal. But the computational cost of attention grows relentlessly with the number of preceding tokens. The longer the context gets, the more attention operations (and therefore computing power) are needed to generate the next token.
This means that the total computing power required for attention grows quadratically with the total number of tokens. Suppose a 10-token prompt requires 414,720 attention operations. Then:
- Processing a 100-token prompt will require 45.6 million attention operations.
- Processing a 1,000-token prompt will require 4.6 billion attention operations.
- Processing a 10,000-token prompt will require 460 billion attention operations.
This is probably why Google charges twice as much, per token, for Gemini 1.5 Pro once the context gets longer than 128,000 tokens. Generating token number 128,001 requires comparisons with all 128,000 previous tokens, making it significantly more expensive than producing the first or 10th or 100th token.
A lot of effort has been put into optimizing attention. One line of research has tried to squeeze maximum efficiency out of individual GPUs.
As we saw earlier, a modern GPU contains thousands of execution units. Before a GPU can start doing math, it must move data from slow shared memory (called high-bandwidth memory) to much faster memory inside a particular execution unit (called SRAM). Sometimes GPUs spend more time moving data around than performing calculations.
In a series of papers, Princeton computer scientist Tri Dao and several collaborators have developed FlashAttention, which calculates attention in a way that minimizes the number of these slow memory operations. Work like Dao’s has dramatically improved the performance of transformers on modern GPUs.
Another line of research has focused on efficiently scaling attention across multiple GPUs. One widely cited paper describes ring attention, which divides input tokens into blocks and assigns each block to a different GPU. It’s called ring attention because GPUs are organized into a conceptual ring, with each GPU passing data to its neighbor.
I once attended a ballroom dancing class where couples stood in a ring around the edge of the room. After each dance, women would stay where they were while men would rotate to the next woman. Over time, every man got a chance to dance with every woman. Ring attention works on the same principle. The “women” are query vectors (describing what each token is “looking for”) and the “men” are key vectors (describing the characteristics each token has). As the key vectors rotate through a sequence of GPUs, they get multiplied by every query vector in turn.
In short, ring attention distributes attention calculations across multiple GPUs, making it possible for LLMs to have larger context windows. But it doesn’t make individual attention calculations any cheaper.
The fixed-size hidden state of an RNN means that it doesn’t have the same scaling problems as a transformer. An RNN requires about the same amount of computing power to produce its first, hundredth and millionth token. That’s a big advantage over attention-based models.
Although RNNs have fallen out of favor since the invention of the transformer, people have continued trying to develop RNNs suitable for training on modern GPUs.
In April, Google announced a new model called Infini-attention. It’s kind of a hybrid between a transformer and an RNN. Infini-attention handles recent tokens like a normal transformer, remembering them and recalling them using an attention mechanism.
However, Infini-attention doesn’t try to remember every token in a model’s context. Instead, it stores older tokens in a “compressive memory” that works something like the hidden state of an RNN. This data structure can perfectly store and recall a few tokens, but as the number of tokens grows, its recall becomes lossier.
Machine learning YouTuber Yannic Kilcher wasn’t too impressed by Google’s approach.
“I’m super open to believing that this actually does work and this is the way to go for infinite attention, but I’m very skeptical,” Kilcher said. “It uses this compressive memory approach where you just store as you go along, you don’t really learn how to store, you just store in a deterministic fashion, which also means you have very little control over what you store and how you store it.”
Perhaps the most notable effort to resurrect RNNs is Mamba, an architecture that was announced in a December 2023 paper. It was developed by computer scientists Dao (who also did the FlashAttention work I mentioned earlier) and Albert Gu.
Mamba does not use attention. Like other RNNs, it has a hidden state that acts as the model’s “memory.” Because the hidden state has a fixed size, longer prompts do not increase Mamba’s per-token cost.
When I started writing this article in March, my goal was to explain Mamba’s architecture in some detail. But then in May, the researchers released Mamba-2, which significantly changed the architecture from the original Mamba paper. I’ll be frank: I struggled to understand the original Mamba and have not figured out how Mamba-2 works.
But the key thing to understand is that Mamba has the potential to combine transformer-like performance with the efficiency of conventional RNNs.
In June, Dao and Gu co-authored a paper with Nvidia researchers that evaluated a Mamba model with 8 billion parameters. They found that models like Mamba were competitive with comparably sized transformers in a number of tasks, but they “lag behind Transformer models when it comes to in-context learning and recalling information from the context.”
Transformers are good at information recall because they “remember” every token of their context—this is also why they become less efficient as the context grows. In contrast, Mamba tries to compress the context into a fixed-size state, which necessarily means discarding some information from long contexts.
The Nvidia team found they got the best performance from a hybrid architecture that interleaved 24 Mamba layers with four attention layers. This worked better than either a pure transformer model or a pure Mamba model.
A model needs some attention layers so it can remember important details from early in its context. But a few attention layers seem to be sufficient; the rest of the attention layers can be replaced by cheaper Mamba layers with little impact on the model’s overall performance.
In August, an Israeli startup called AI21 announced its Jamba 1.5 family of models. The largest version had 398 billion parameters, making it comparable in size to Meta’s Llama 405B model. Jamba 1.5 Large has seven times more Mamba layers than attention layers. As a result, Jamba 1.5 Large requires far less memory than comparable models from Meta and others. For example, AI21 estimates that Llama 3.1 70B needs 80GB of memory to keep track of 256,000 tokens of context. Jamba 1.5 Large only needs 9GB, allowing the model to run on much less powerful hardware.
The Jamba 1.5 Large model gets an MMLU score of 80, significantly below the Llama 3.1 70B’s score of 86. So by this measure, Mamba doesn’t blow transformers out of the water. However, this may not be an apples-to-apples comparison. Frontier labs like Meta have invested heavily in training data and post-training infrastructure to squeeze a few more percentage points of performance out of benchmarks like MMLU. It’s possible that the same kind of intense optimization could close the gap between Jamba and frontier models.
So while the benefits of longer context windows is obvious, the best strategy to get there is not. In the short term, AI companies may continue using clever efficiency and scaling hacks (like FlashAttention and Ring Attention) to scale up vanilla LLMs. Longer term, we may see growing interest in Mamba and perhaps other attention-free architectures. Or maybe someone will come up with a totally new architecture that renders transformers obsolete.
But I am pretty confident that scaling up transformer-based frontier models isn’t going to be a solution on its own. If we want models that can handle billions of tokens—and many people do—we’re going to need to think outside the box.
Tim Lee was on staff at Ars from 2017 to 2021. Last year, he launched a newsletter, Understanding AI, that explores how AI works and how it's changing our world. You can subscribe here.

Timothy is a senior reporter covering tech policy and the future of transportation. He lives in Washington DC.





 English (US) ·
English (US) ·