
In brief
- Reve integrates web browsing, pulling real logos and references directly into edits.
- Nano Banana sets a new standard for character consistency, but suffers from strict censorship.
- Qwen 3 Omni Flash excels at multi-element compositions, but lags on subject fidelity.
- Local models like Flux Kontext or Qwen Image Edit provide full creative freedom without quotas or filters.
The era of mastering controlnets, wrestling with inpainting masks, and memorizing arcane prompt engineering formulas has officially ended. Those convoluted workflows that required understanding style references, LORAs, and image-to-image pipelines have been replaced by something remarkably simple: typing what you want in plain English.
Understanding the fundamental distinction between image generators and image editors is important as these tools converge. Traditional generators like FLUX 1 Dev or Google's Imagen create images from nothing—transforming text prompts into pixels through pure synthesis.
On the other hand, image editors like FLUX Kontext and Nano Banana operate differently, taking existing images and modifying them according to instructions while preserving core elements.
The line blurs increasingly as models gain dual capabilities, but the underlying architecture differs significantly. Generators optimize for creative freedom and aesthetic quality from blank canvases, while editors prioritize preservation of existing elements, precise local changes, and maintaining consistency across modifications.
ChatGPT kicked off this revolution with its integrated DALL-E capabilities, bringing image editing to the conversational AI masses. The implementation was straightforward—describe your edits, and watch them happen.
Yet ChatGPT's visual outputs leaned heavily toward the cartoonish, producing results that felt more like concept art than finished products. The realism factor remained elusive, and serious creators quickly moved on.
Then Google dropped Nano Banana—technically Gemini 2.5 Flash Image—and the entire landscape shifted. The model's character consistency capabilities set new benchmarks, maintaining subject identity across multiple generations with unprecedented accuracy. Suddenly, the bar for what constituted "good" image editing rocketed skyward.
Since then, the AI space has received quite a few new models, each one with its own strengths and weaknesses. If you want to know which one is the best for you, keep reading. Here is our comparison, review, and explanation of what you will love and hate about the best image editors to date.
Reve Art: The Swiss Army knife that thinks
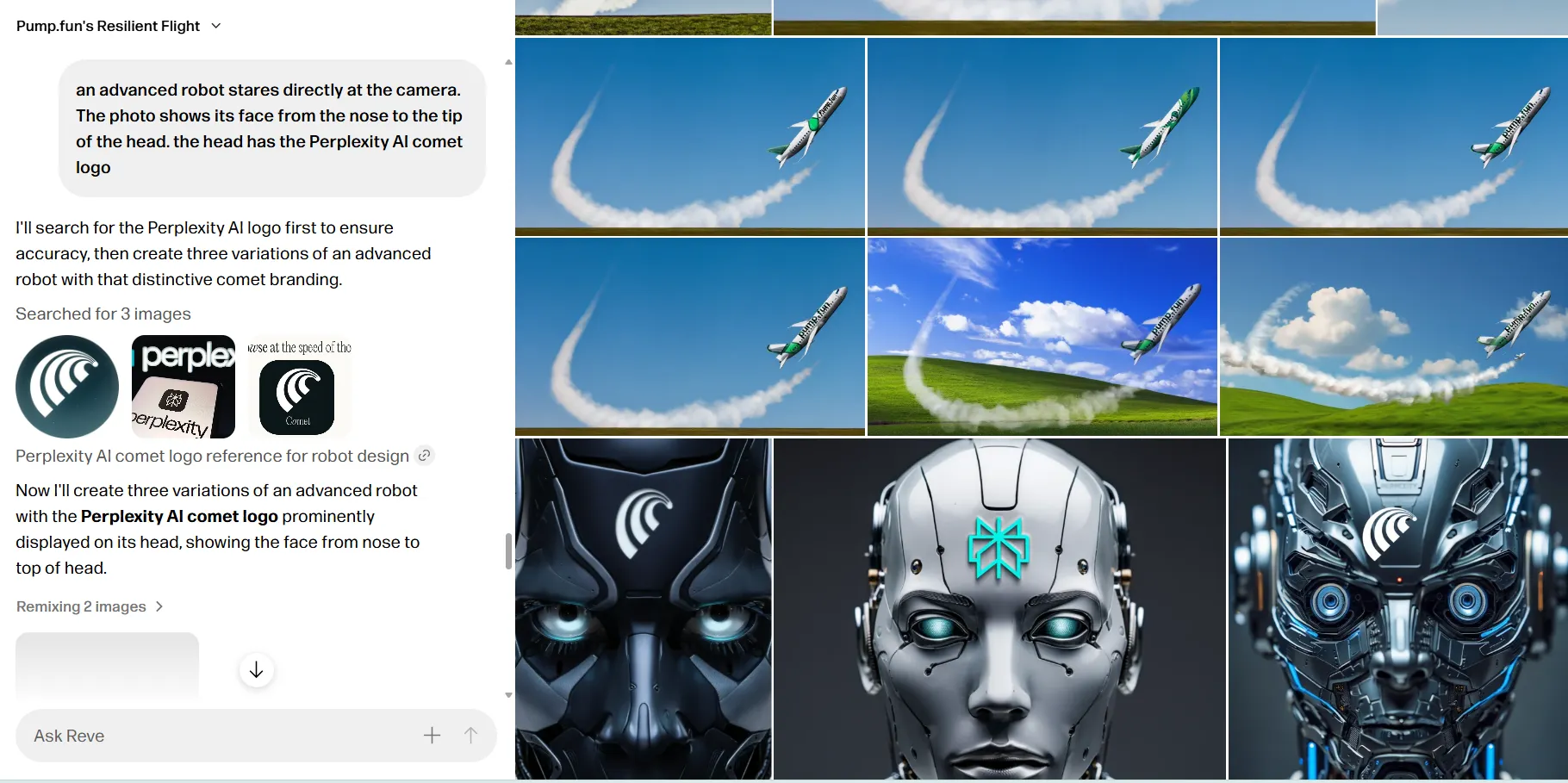
Reve has undergone a complete transformation since its preview phase. The interface overhaul reflects a fundamental shift in approach—instead of functioning as another image generator or editor, Reve operates like an AI assistant that happens to excel at visual tasks.
The model's killer feature is its ability to browse the web and incorporate real-world elements into generations.
For example, when asked to include the Google logo in an image, then replace it with Decrypt's logo, Reve didn't hallucinate a close approximation. The model searched the web, located the actual Decrypt logo, understood the compositional context, and seamlessly integrated it into the existing image. No manual uploads, no reference images, no prayers to the AI gods.
This web-browsing capability solves a fundamental limitation of traditional models which don’t really browse the web for content. Training on every logo, phrase, or public figure would require ingesting the entire internet—an impossibility. Reve sidesteps this by fetching specific information on demand, ensuring accuracy without bloated training datasets.
The model also excels at artistic diversity, generating images across multiple styles with greater accuracy than its competitors. While others chase photorealism, Reve maximizes creative expression. Speed remains impressive, and the combination of generation and editing capabilities feels genuinely unified rather than bolted together.
Nano Banana: The consistency king with a conservative streak
Google's Gemini 2.5 Flash Image—universally known as Nano Banana after its viral community nickname—has become the gold standard for character consistency. The model demonstrates an almost uncanny ability to understand subject characteristics and translate them accurately across different scenes and contexts.
For anyone editing photos with specific characters, this is the model. Traditional AI editing creates images from scratch, making AI intervention obvious through subtle distortions and inconsistencies. Nano Banana minimizes these telltale signs, producing edits that maintain the original subject's integrity.
The model's architectural focus on subject identity maintenance means placing the same character in various scenes, showcasing products from multiple angles, or ensuring brand asset consistency becomes trivially easy. Google integrated visual reasoning capabilities that allow the model to understand not just what to generate, but why certain elements should remain consistent.
However, Nano Banana comes with significant limitations. The censorship is aggressive—even simple meme concepts involving cartoon animals in conflict trigger content warnings. Google's safety filters count blocked outputs against user quotas, meaning experimentation becomes expensive quickly. The model refuses edits seemingly at random, sometimes rejecting innocuous requests that fall nowhere near content policy violations.
Creative flexibility suffers under these constraints. Users requiring numerous iterations or extensive generation sessions hit quota limits fast, forcing upgrades to pro ($20) or ultra ($250) subscriptions. The combination of limited outputs and zealous censorship creates a frustrating experience for anyone pushing creative boundaries.
Qwen Omni Flash: The multi-element master
Alibaba's Qwen 3 Omni Flash shines in complex, multi-element scenarios. Upload a subject image, add a posing reference, and watch the model parse both contexts simultaneously. While facial features might drift slightly, the model respects compositional requirements where others fail.
It is by far the best model if your inputs require elements from different images
Content restrictions are not as strong as Nano Banana's strictness. The model allows more creative freedom than Google's offering while maintaining basic safety guidelines. Credit allocation proves more generous too—12-hour cooldowns versus Nano Banana's 24-hour waits mean faster iteration cycles.
Character consistency remains the weak point. It is very good, yes, but not as consistent as Nano Banana. While Qwen handles complex scenes admirably, maintaining precise subject identity across generations proves challenging. The model trades absolute fidelity for compositional accuracy—a worthwhile exchange for certain workflows but frustrating for others.
Local alternatives: Power vs. accessibility
If you want to go for full autonomy and control over your generations, then the local route is the way to go. Beware, though: You’ll need some pretty powerful hardware if you decide to get your hands dirty and host your own models.
Qwen Image Edit is the beginner-friendly local option. Natural, reliable edits make it ideal for multi-image workflows and subtle photo adjustments. The open-source nature means you have full control over content and processing, though the computational requirements—significant VRAM and processing power—limit accessibility.
In second place for quality is the good ol' Flux Kontext. Artists praise its output quality in dynamic scenarios, particularly for background replacement and style transitions. Running on 6GB VRAM cards with heavy quantization makes it surprisingly accessible, and the extensive community resources provide solutions for nearly any workflow imaginable.
This will be, by far, the best and cheapest local and uncensored option for enthusiasts to play around with. It also makes it easier to incorporate complex workflows, so users can have an extremely granular level of control over the changes and edits they want to make on their images.
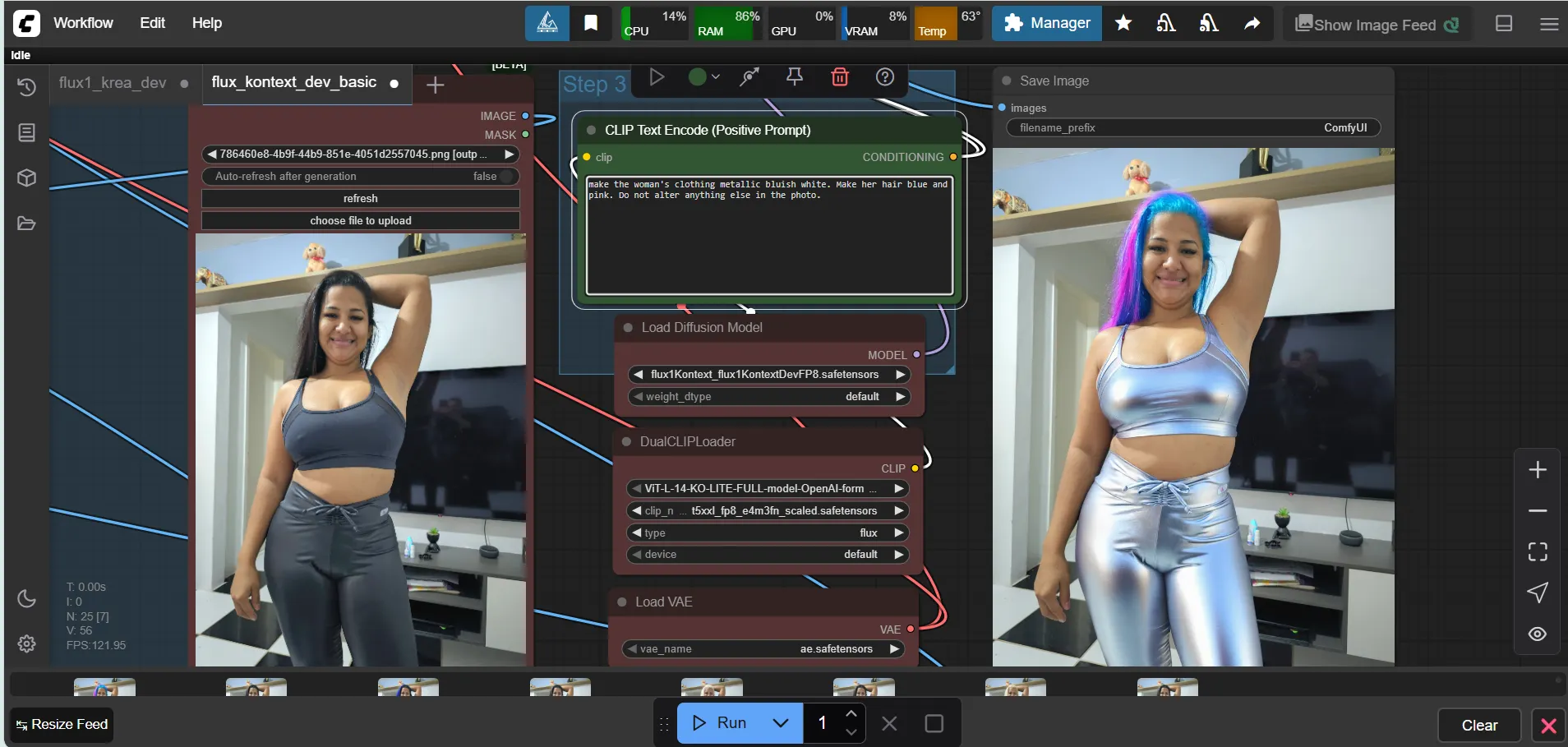
The local advantage becomes clear for NSFW content or sensitive workflows. No API restrictions, no content filters, no usage quotas—just pure processing power determining capabilities.
It may not be the most accurate in terms of subject consistency, though some nice prompt engineering and a few different iterations may help. But if you decide to use this model locally in a ComfyUI workflow, then you may be advanced enough to know about all the plugins and resources that can make these models as powerful as the state-of-the-art models offered by AI giants.
So with a custom-trained LoRA, a ReActor node for faceswaps, and some controlnets here and there, you may have an image that resembles exactly what you have in mind.
Testing the models
Here are some comparisons that better showcase the models' strengths and weaknesses.
Multi Element edit:
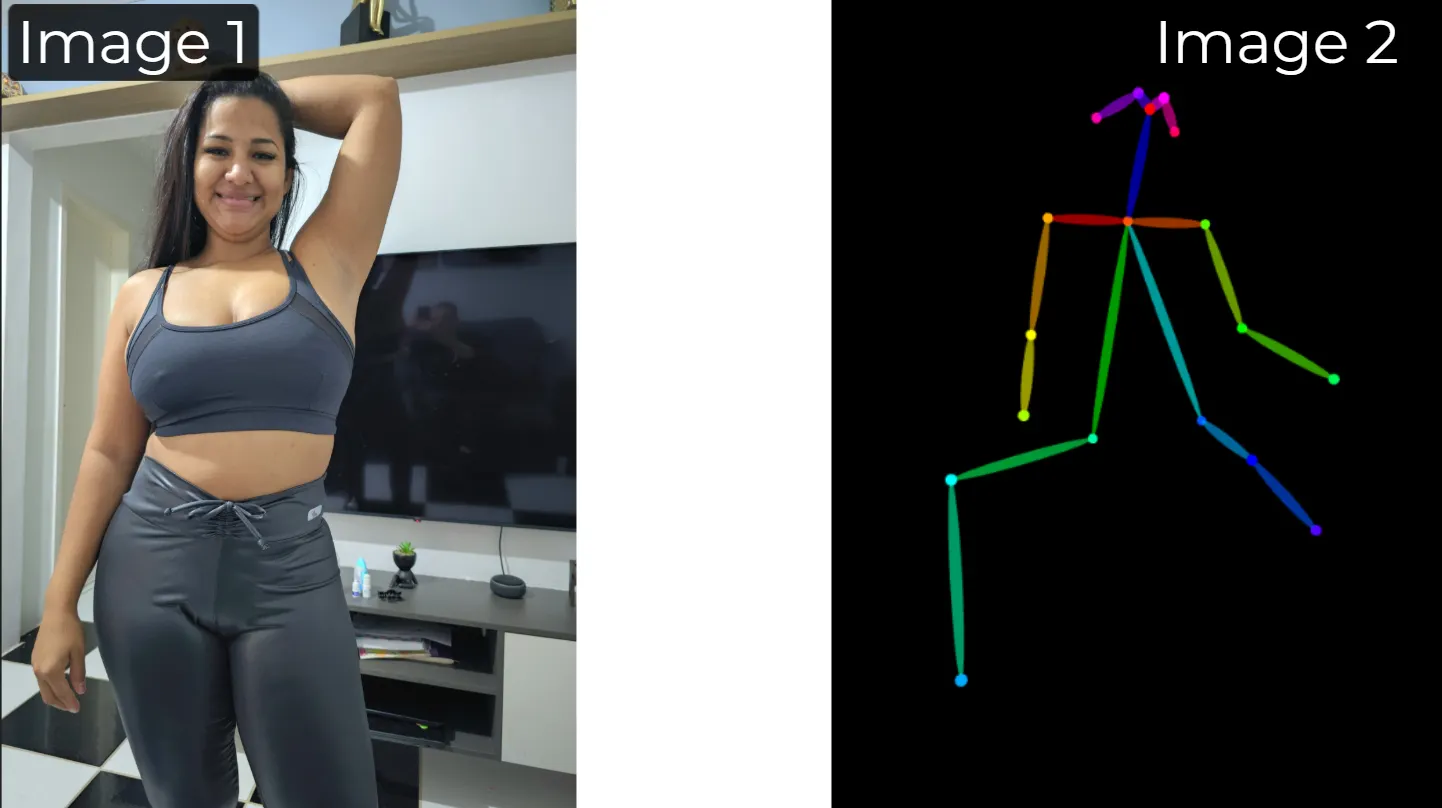
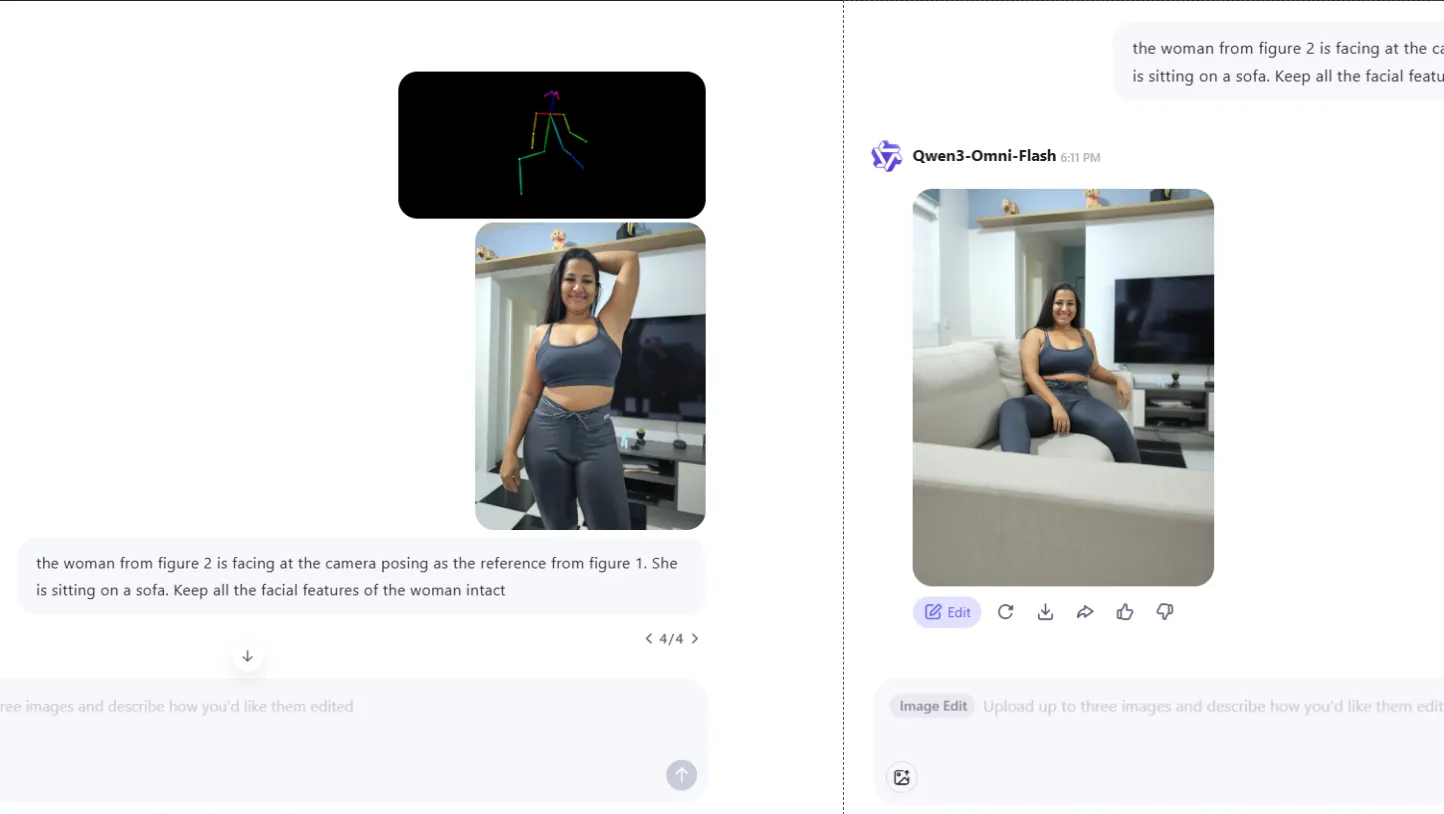
Visual input:
Prompt: the woman from figure 2 is facing the camera posing as the reference from figure 1. She is sitting on a sofa. Keep all the facial features of the woman intact
Outputs:

Model Analysis:
- Reve: Good at integrating references especially when content needs to be pulled from real-world data. Handles compositional requirements very well. However, it could not transfer the pose from the visual input.
- Nano Banana: Maintains character identity solidly, but fails at combining multiple reference elements. The pose was not respected and was less consistent than Reve.
- Qwen Omni Flash: Best here. This model handles multi-element blending and contextual understanding the strongest. It parsed both the main image and reference for pose, with above-average accuracy in combining inputs.
Winner: Qwen Omni Flash — the best at managing and accurately blending complex, multi-element instructions.
Character consistency

Visual input:
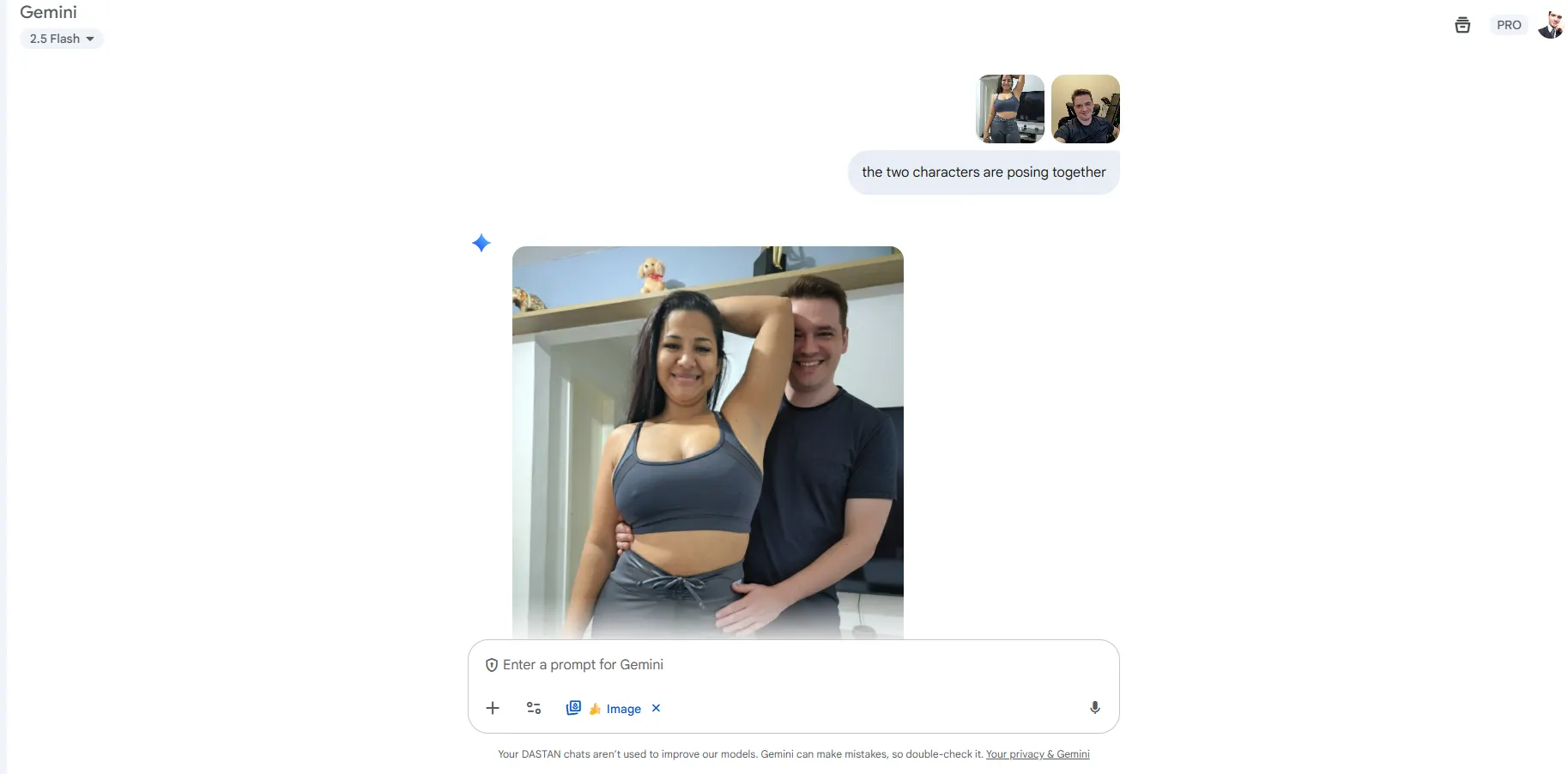
Prompt: Make the two subjects pose together
Outputs:

Model Analysis:
- Reve: Very good at composition, but not always the best with strict face/identity consistency across edits.
- Nano Banana: Best here. Sets the standard for subject identity across generations. Maintains consistent details for both subjects, even in varied contexts or poses.
- Qwen Omni Flash: Character consistency may not be as unwavering as Nano Banana. The generations fail at depicting the reference image.
Winner: Nano Banana — it's unmatched at maintaining subject identity and details across scenes.
Creativity/non-realism:

Visual input:
Prompt: turn this into an epic Van Gogh. Make the man meditative and holding a bitcoin
Outputs:

Model Analysis:
- Reve: Best here. This may be more subjective, but in our opinion, Reve excels at artistic diversity and creative interpretations. The engine’s focus is on maximizing expression across styles. It is also the most consistent—meaning it provides good results most of the times.
- Nano Banana: Good at style transfer, but tends to be safer, applies stricter filters, and may not be as flexible or creative as Reve. The face is basically a copy of the realistic image instead of an artistic representation.
- Qwen Omni Flash: Strong compositional abilities, but creativity and stylization trail Reve. Subjectively, the output was not as good as Reve, but still a bit more satisfactory than Nano Banana’s output.
Winner: Reve — the best choice for creative, artistic, or non-literal transformations.
Unusual elements (not in the model’s training dataset)

Visual input:
Prompt: change the google logo for the Decrypt.co logo

Model Analysis:
- Reve: Best here. Uses web browsing to fetch the actual logo, ensuring real-world accuracy, rather than hallucinating or guessing from its training data.
- Nano Banana: Lacks the ability to fetch real-time assets, so it might substitute a generic or similar logo from its training set.
- Qwen Omni Flash: Same as Nano Banana. The model lacks live web search; would try to approximate from dataset knowledge.
Winner: Reve — it's uniquely suited for inserting novel elements by accessing real-world references on-demand.
Verdict: Matching models to workflows
Reve suits creative professionals who need versatility without technical overhead. The web-browsing capability makes it invaluable for brand work requiring accurate logos or current references. Marketing teams, graphic designers, and content creators who value speed and creative diversity over absolute photorealism will find Reve indispensable.
Nano Banana belongs in pipelines requiring unwavering consistency. Product photographers maintaining catalog coherence, character designers needing stable references across scenes, and developers building consumer-facing applications where safety matters—these users will tolerate the restrictions for the consistency payoff.
Qwen Omni Flash serves studios handling complex, multi-layered compositions. The model's ability to juggle multiple elements while maintaining reasonable generation speed makes it ideal for concept artists, storyboard creators, and anyone building scenes rather than isolated subjects.
Local solutions like Flux Kontext and Qwen Image Edit attract power users with specific requirements, or users expecting to do a big number of edits and iterations with little to no budget at all. Independent artists requiring complete creative control, folks wanting to edit images for "research purposes," and developers building specialized applications—these users accept the infrastructure burden for absolute freedom.
Another solid contender is Bytedance’s Seedream v4. It is pretty competitive, and some praise it as a Nano Banana killer. However, there is no option to test it for free, which is why we left it off of this list.
The transformation from technical complexity to natural language simplicity has democratized professional image editing. Models now compete not on raw capability but on specialization, each carving out niches where they excel. The prompt engineering textbooks can be retired. The future speaks plain English.
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.







 English (US) ·
English (US) ·