
Serving tech enthusiasts for over 25 years.
TechSpot means tech analysis and advice you can trust.
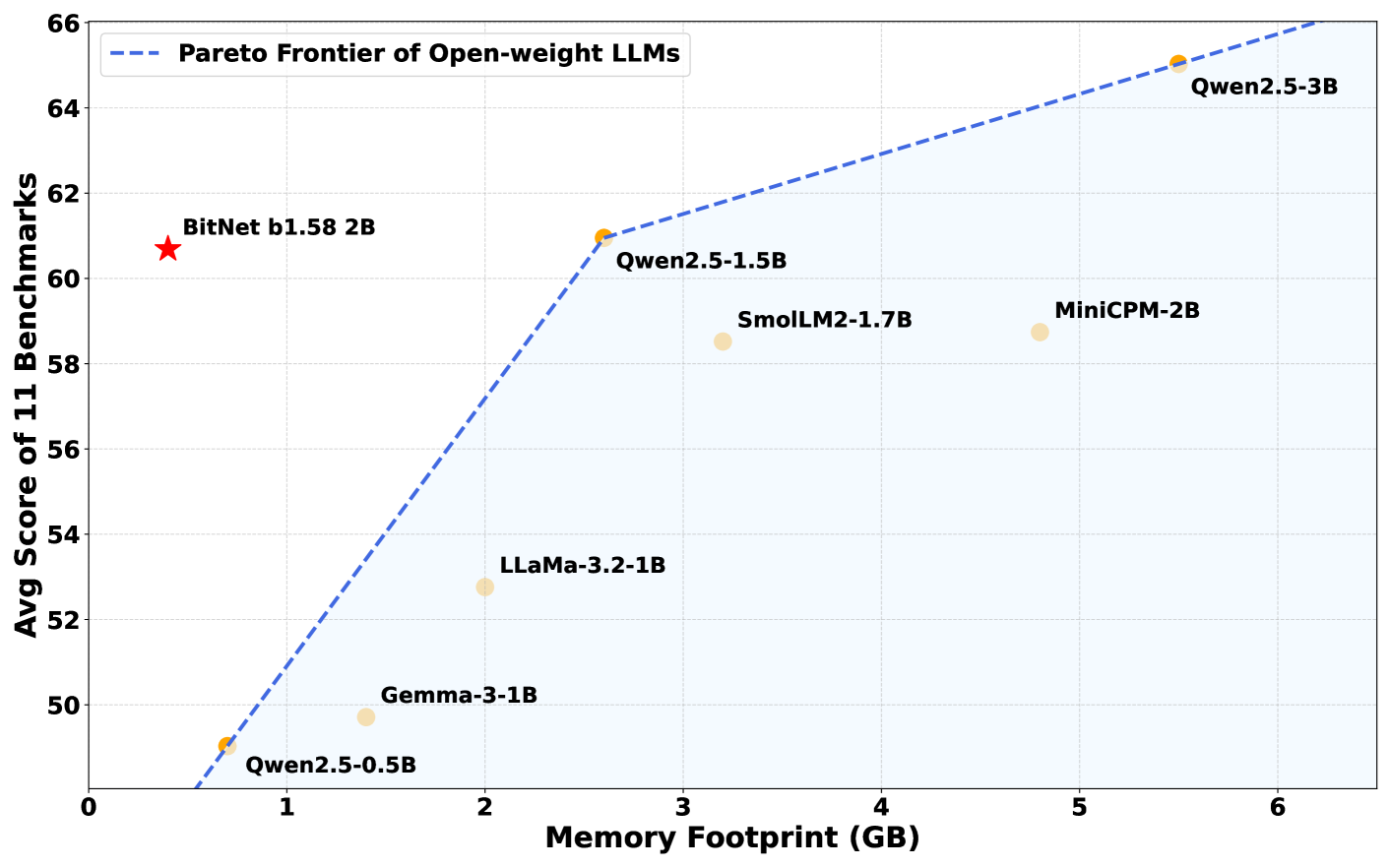
What just happened? Microsoft has introduced BitNet b1.58 2B4T, a new type of large language model engineered for exceptional efficiency. Unlike conventional AI models that rely on 16- or 32-bit floating-point numbers to represent each weight, BitNet uses only three discrete values: -1, 0, or +1. This approach, known as ternary quantization, allows each weight to be stored in just 1.58 bits. The result is a model that dramatically reduces memory usage and can run far more easily on standard hardware, without requiring the high-end GPUs typically needed for large-scale AI.
The BitNet b1.58 2B4T model was developed by Microsoft's General Artificial Intelligence group and contains two billion parameters – internal values that enable the model to understand and generate language. To compensate for its low-precision weights, the model was trained on a massive dataset of four trillion tokens, roughly equivalent to the contents of 33 million books. This extensive training allows BitNet to perform on par with – or in some cases, better than – other leading models of similar size, such as Meta's Llama 3.2 1B, Google's Gemma 3 1B, and Alibaba's Qwen 2.5 1.5B.
In benchmark tests, BitNet b1.58 2B4T demonstrated strong performance across a variety of tasks, including grade-school math problems and questions requiring common sense reasoning. In certain evaluations, it even outperformed its competitors.
What truly sets BitNet apart is its memory efficiency. The model requires just 400MB of memory, less than a third of what comparable models typically need. As a result, it can run smoothly on standard CPUs, including Apple's M2 chip, without relying on high-end GPUs or specialized AI hardware.
This level of efficiency is made possible by a custom software framework called bitnet.cpp, which is optimized to take full advantage of the model's ternary weights. The framework ensures fast and lightweight performance on everyday computing devices.
Standard AI libraries like Hugging Face's Transformers don't offer the same performance advantages as BitNet b1.58 2B4T, making the use of the custom bitnet.cpp framework essential. Available on GitHub, the framework is currently optimized for CPUs, but support for other processor types is planned in future updates.
The idea of reducing model precision to save memory isn't new as researchers have long explored model compression. However, most past attempts involved converting full-precision models after training, often at the cost of accuracy. BitNet b1.58 2B4T takes a different approach: it is trained from the ground up using only three weight values (-1, 0, and +1). This allows it to avoid many of the performance losses seen in earlier methods.
This shift has significant implications. Running large AI models typically demands powerful hardware and considerable energy, factors that drive up costs and environmental impact. Because BitNet relies on extremely simple computations – mostly additions instead of multiplications – it consumes far less energy.
Microsoft researchers estimate it uses 85 to 96 percent less energy than comparable full-precision models. This could open the door to running advanced AI directly on personal devices, without the need for cloud-based supercomputers.
That said, BitNet b1.58 2B4T does have some limitations. It currently supports only specific hardware and requires the custom bitnet.cpp framework. Its context window – the amount of text it can process at once – is smaller than that of the most advanced models.
Researchers are still investigating why the model performs so well with such a simplified architecture. Future work aims to expand its capabilities, including support for more languages and longer text inputs.








 English (US) ·
English (US) ·