
In the summer of 2017, a group of Google Brain researchers quietly published a paper that would forever change the trajectory of artificial intelligence. Titled "Attention Is All You Need," this academic publication didn't arrive with splashy keynotes or frontpage news. Instead, it debuted at the Neural Information Processing Systems (NeurIPS) conference, a technical gathering where cutting-edge ideas often simmer for years before they reach the mainstream.
Few outside the AI research community knew it at the time, but this paper would lay the groundwork for nearly every major generative AI model you've heard of today from OpenAI's GPT to Meta's LLaMA variants, BERT, Claude, Bard, you name it.
The Transformer is an innovative neural network architecture that sweeps away the old assumptions of sequence processing. Instead of linear, step-by-step processing, the Transformer embraces a parallelizable mechanism, anchored in a technique known as self-attention. Over a matter of months, the Transformer revolutionized how machines understand language.

Some of the illustrations in this article were generated by AI. Masthead prompt: giant robot towering above city landscape in style of Eva-01 from Neon Genesis Evangelion by Gainax, 4k. Image above, 3d render by BoliviaInteligente.
A New Model
Before the Transformer, state-of-the-art natural language processing (NLP) hinged heavily on recurrent neural networks (RNNs) and their refinements – LSTMs (Long Short-Term Memory networks) and GRUs (Gated Recurrent Units). These recurrent neural networks processed text word-by-word (or token-by-token), passing along a hidden state that was meant to encode everything read so far.
This process felt intuitive... after all, we read language from left to right, so why shouldn't a model?
But these older architectures came with critical shortcomings. For one, they struggled with very long sentences. By the time an LSTM reached the end of a paragraph, the context from the beginning often felt like a faded memory. Parallelization was also difficult because each step depended on the previous one. The field desperately needed a way to process sequences without being stuck in a linear rut.
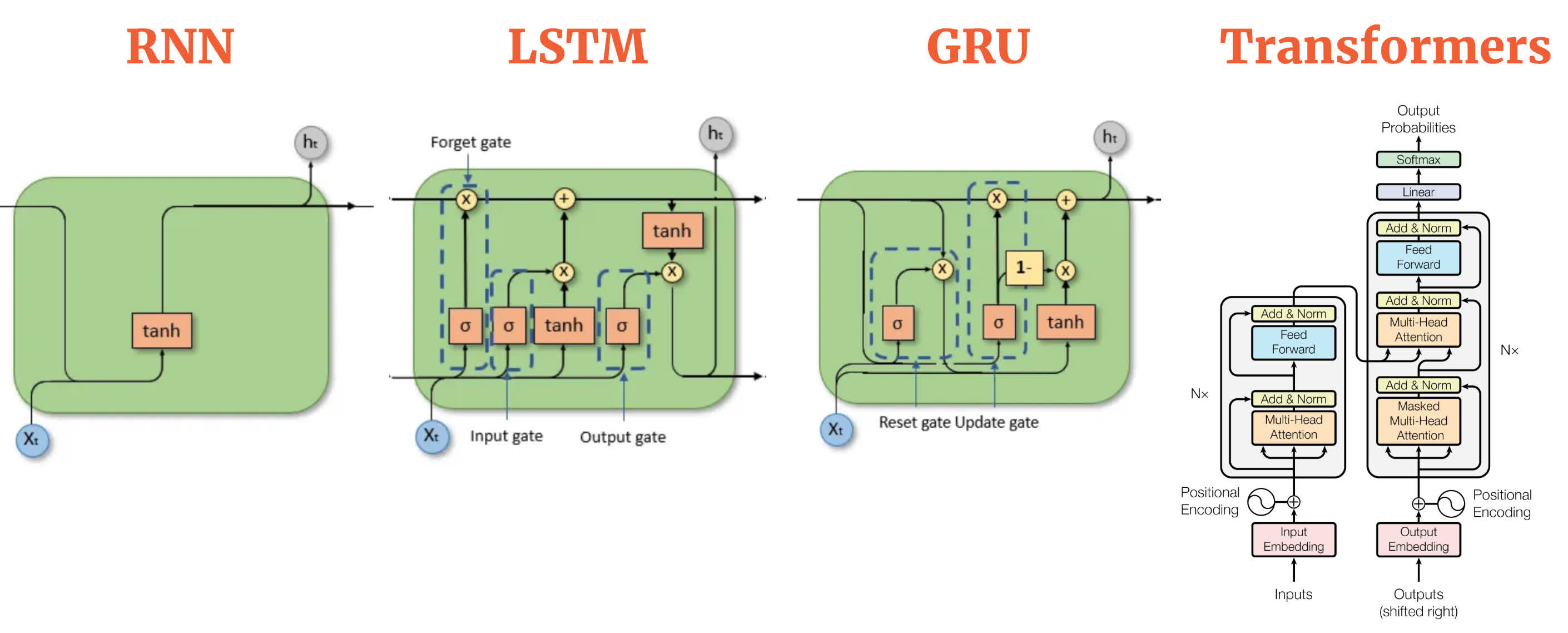
Comparison of RNN, LSTM, GRU, and Transformer architectures, highlighting their key components and mechanisms for processing sequential data. Source: aiml.com
Google Brain researchers set out to change that dynamic. Their solution was deceptively simple: ditch recurrence altogether. Instead, they designed a model that could look at every word in a sentence simultaneously and figure out how each word related to every other word.
This clever trick – called the "attention mechanism" – let the model focus on the most relevant parts of a sentence without the computational baggage of recurrence. The result was the Transformer: fast, parallelizable, and bizarrely good at handling context over long stretches of text.
The breakthrough idea was that "attention," not sequential memory, could be the true engine of understanding language. Attention mechanisms had existed in earlier models, but the Transformer elevated attention from a supporting role to the star of the show. Without the Transformer's full-attention framework, generative AI as we know it would likely still be stuck in slower, more limited paradigms.

Serendipity and AI.
Image prompt: the meaning of life
But how did this idea come about at Google Brain? The backstory is sprinkled with the kind of serendipity and intellectual cross-pollination that defines AI research. Insiders talk about informal brainstorming sessions, where researchers from different teams compared notes on how attention mechanisms were helping solve translation tasks or improve alignment between source and target sentences.
There were coffee-room debates over whether the necessity of recurrence was just a relic of old thinking. Some researchers recall "corridor coaching sessions" where a then-radical idea – removing RNNs entirely – was floated, challenged, and refined before the team finally decided to commit it to code.
Part of the brilliance of the transformer is that it made it possible to train on huge datasets very quickly and efficiently.
The Transformer's architecture uses two main parts: an encoder and a decoder. The encoder processes the input data and creates a detailed, meaningful representation of that data using layers of self-attention and simple neural networks. The decoder works similarly but focuses on the previously generated output (like in text generation) while also using information from the encoder.
Part of the brilliance of this design is that it made it possible to train on huge datasets very quickly and efficiently. An oft-repeated anecdote from the early days of the Transformer's development is that some Google engineers didn't initially realize the extent of the model's potential.
They knew it was good – much better than previous RNN-based models at certain language tasks – but the idea that this could revolutionize the entire field of AI was still unfolding. It wasn't until the architecture was publicly released and enthusiasts worldwide began experimenting that the true power of the Transformer became undeniable.
A Renaissance in Language Models
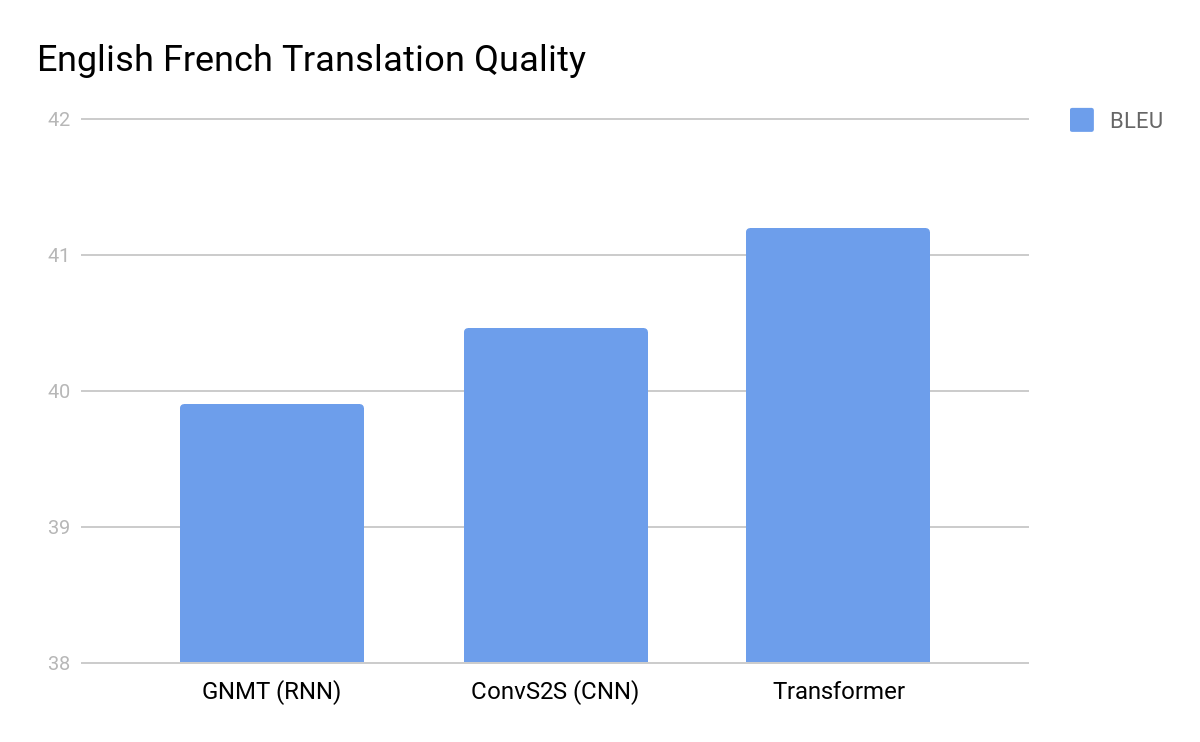
When Google Brain published the 2017 paper, the NLP community reacted first with curiosity, then with astonishment. The Transformer architecture was seen outperforming the best machine translation models at tasks like the WMT English-to-German and English-to-French benchmarks. But it wasn't just the performance – researchers quickly realized the Transformer was orders of magnitude more parallelizable. Training times plummeted. Suddenly, tasks that once took days or weeks could be done in a fraction of the time on the same hardware.
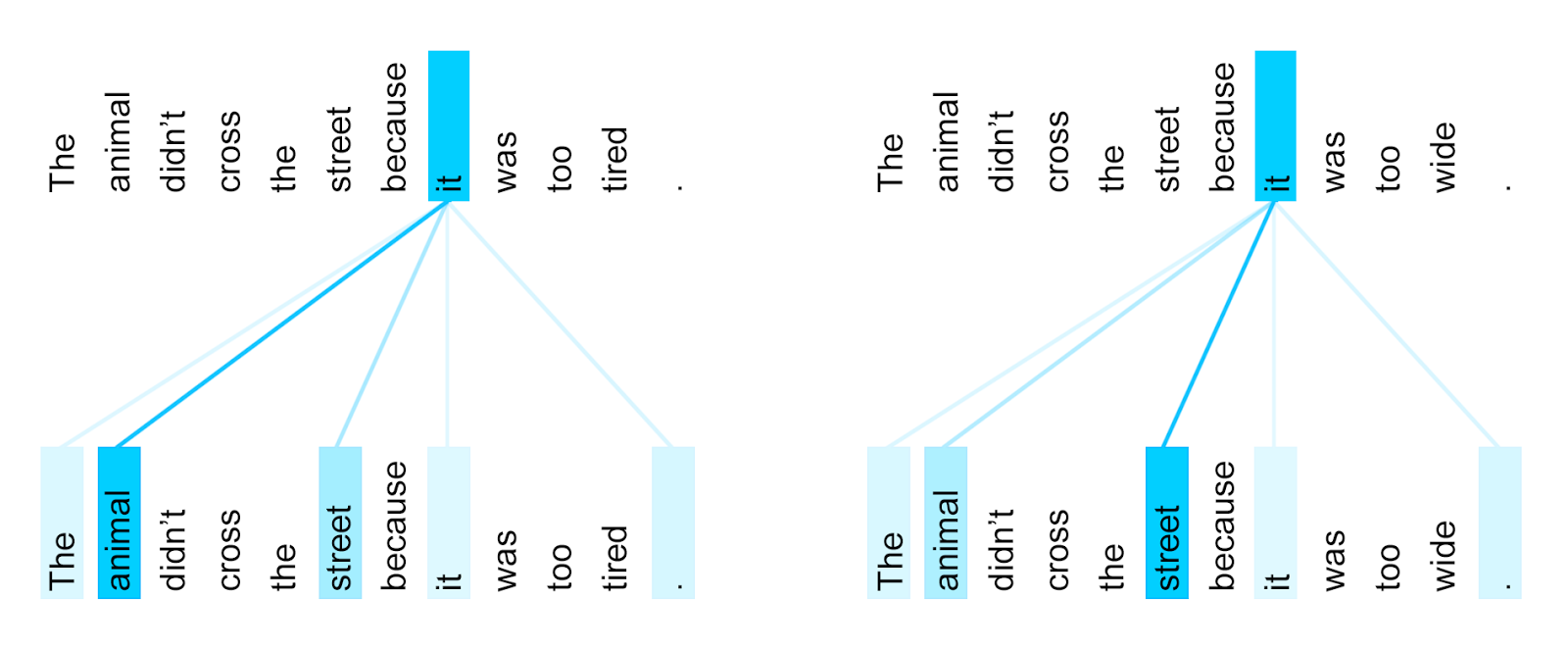
The encoder's self-attention pattern for the word "it," observed between the 5th and 6th layers of a Transformer model trained for English-to-French translation
Within a year of its introduction, the Transformer model had inspired a wave of innovations. Google itself leveraged the Transformer architecture to create BERT (Bidirectional Encoder Representations from Transformers). BERT drastically improved the way machines understood language, taking the top spot on many NLP benchmarks. It soon found its way into everyday products like Google Search, quietly enhancing how queries were interpreted.
Media outlets discovered GPT's prowess and showcased countless examples – sometimes jaw-dropping, sometimes hilariously off-base.
Almost simultaneously, OpenAI took the Transformer blueprint and went in another direction with GPT (Generative Pre-trained Transformers).
GPT-1 and GPT-2 hinted at the power of scaling. By GPT-3, it became impossible to ignore how good these systems were at producing human-like text and reasoning through complex prompts.
The first ChatGPT version (late 2022) used a further refined GPT-3.5 model, it was a watershed moment. ChatGPT could generate eerily coherent text, translate languages, write code snippets, and even produce poetry. Suddenly, a machine's ability to produce human-like text was no longer a pipe dream but a tangible reality.

Media outlets discovered GPT's prowess and showcased countless examples – sometimes jaw-dropping, sometimes hilariously off-base. The public was both thrilled and unnerved. The idea of AI-assisted creativity moved from science fiction to everyday conversation. This wave of progress – fueled by the Transformer – transformed AI from a specialized tool into a general-purpose reasoning engine.
But the Transformer isn't just good at text. Researchers found that attention mechanisms could work across different types of data – images, music, code.
But the Transformer isn't just good at text. Researchers found that attention mechanisms could work across different types of data – images, music, code. Before long, models like CLIP and DALL-E were blending textual and visual understanding, generating "unique" art or labeling images with uncanny accuracy. Video understanding, speech recognition, and even scientific data analysis began to benefit from this same underlying blueprint.
In addition, software frameworks like TensorFlow and PyTorch incorporated Transformer-friendly building blocks, making it easier for hobbyists, startups, and industry labs to experiment. Today, it's not uncommon to see specialized variants of the Transformer architecture pop up in everything from biomedical research to financial forecasting.
The Race to Bigger Models
A key discovery that emerged as researchers continued to push Transformers was the concept of scaling laws. Experiments by OpenAI and DeepMind found that as you increase the number of parameters in a Transformer and the size of its training dataset, performance continues to improve in a predictable manner. This linearity became an invitation for an arms race of sorts: bigger models, more data, more GPUs.
Experiments found that as you increase the number of parameters in a Transformer and the size of its training dataset, performance continues to improve in a predictable manner... this linearity became an invitation for an arms race of sorts: bigger models, more data, more GPUs.
Google, OpenAI, Microsoft, and many others have poured immense resources into building colossal Transformer-based models. GPT-3 was followed by even larger GPT-4, while Google introduced models like PaLM with hundreds of billions of parameters. Although these gargantuan models produce more fluent and knowledgeable outputs, they also raise new questions about cost, efficiency, and sustainability.
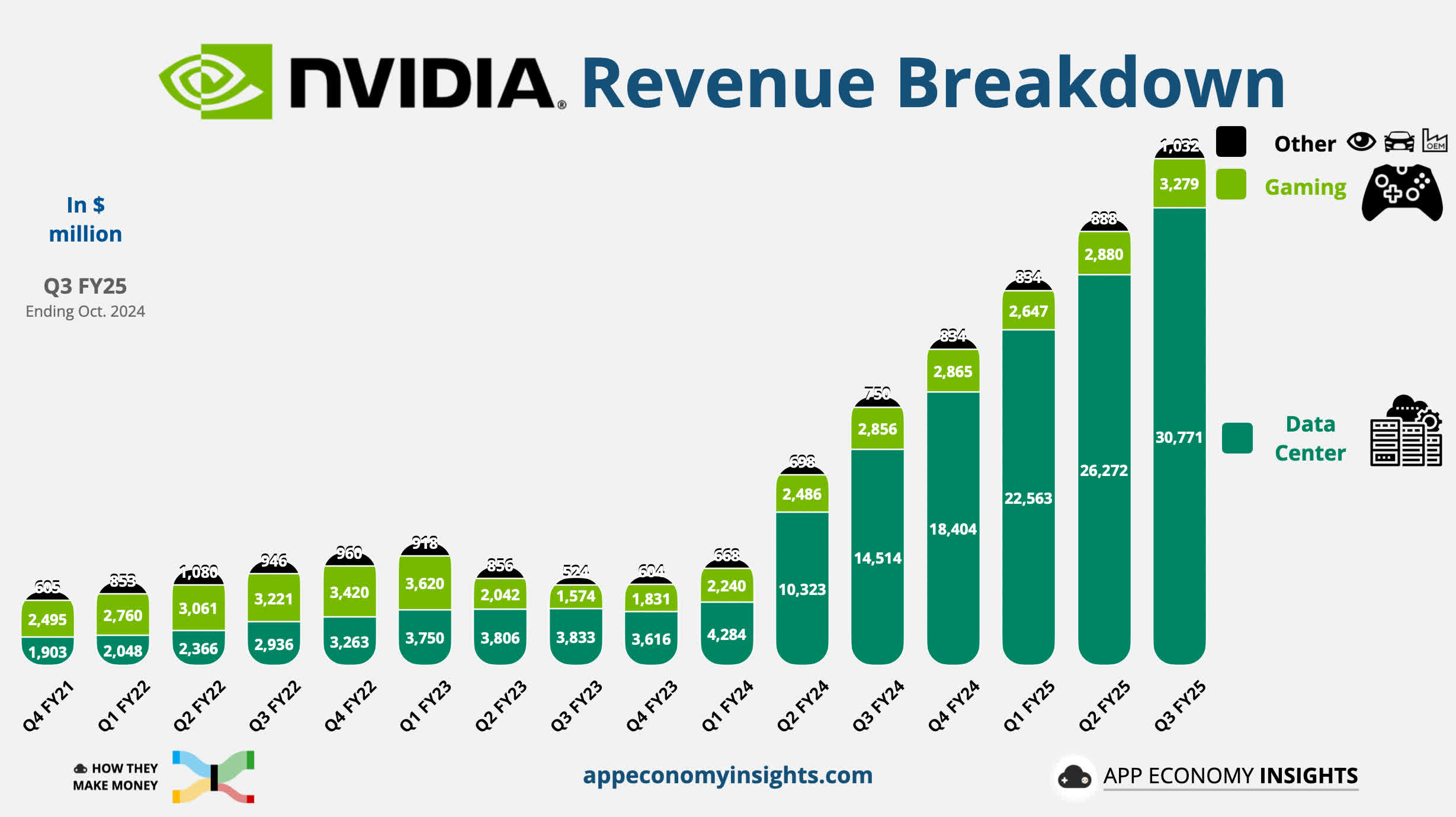
GPUs were originally designed for gaming and 3D rendering. For a while the chips gained popularity in cryptomining before becoming essential for AI training. Nvidia leads the market with most of its chip sales driven by data centers and AI applications.
Training such models consumes enormous computing power (Nvidia is too happy about that one) and electricity – transforming AI research into an endeavor that is much closer today to industrial engineering than the academic tinkering it once was.
Attention Everywhere
ChatGPT has become a cultural phenomenon, breaking out of tech circles and industry discussions to spark dinner table conversations about AI-generated content. Even people who aren't tech-savvy now have some awareness that "there's this AI that can write this for me" or talk to me "like a human." Meanwhile, high school students are increasingly turning to GPT queries instead of Google or Wikipedia for answers.
But all technological revolutions come with side effects, and the Transformer's influence on generative AI is no exception. Even at this early stage, GenAI models have ushered in a new era of synthetic media, raising tricky questions about copyright, misinformation, impersonations of public figures, and ethical deployment.
The same Transformer models that can generate convincingly human prose can also produce misinformation and toxic outputs. Biases can and will be present in the training data, which can be subtly embedded and amplified in the responses offered by GenAI models. As a result, governments and regulatory bodies are beginning to pay close attention. How do we ensure these models don't become engines of disinformation? How do we protect intellectual property when models can produce text and images on demand?
Researchers and the companies developing today's dominant models have started to integrate fairness checks, establish guardrails, and prioritize the responsible deployment of generative AI (or so they say). However, these efforts are unfolding in a murky landscape, as significant questions remain about how these models are trained and where big tech companies source their training data.
The "Attention Is All You Need" paper remains a testament to how open research can drive global innovation. By publishing all the key details, the paper allowed anyone – competitor or collaborator – to build on its ideas. That spirit of openness by Google's team, fueled the astonishing speed at which the Transformer architecture has spread across the industry.
We are only beginning to see what happens as these models become more specialized, more efficient, and more widely accessible. The machine learning community was in dire need for a model that could handle complexity at scale, and self-attention so far has delivered. From machine translation to chatbots that can carry on diverse conversations, from image classification to code generation. Transformers have become the default backbone for natural language processing and then some. But researchers are still wondering: is attention truly all we need?

Skynet and The Terminator 40 years later...
the sci-fi cult classic that still shapes how we view the threat of AI
New architectures are already emerging, such as Performer, Longformer, and Reformer, aiming to improve the efficiency of attention for very long sequences. Others are experimenting with hybrid approaches, combining Transformer blocks with other specialized layers. The field is anything but stagnant.
Moving forward, each new proposal will garner scrutiny, excitement, and why not, fear.








 English (US) ·
English (US) · 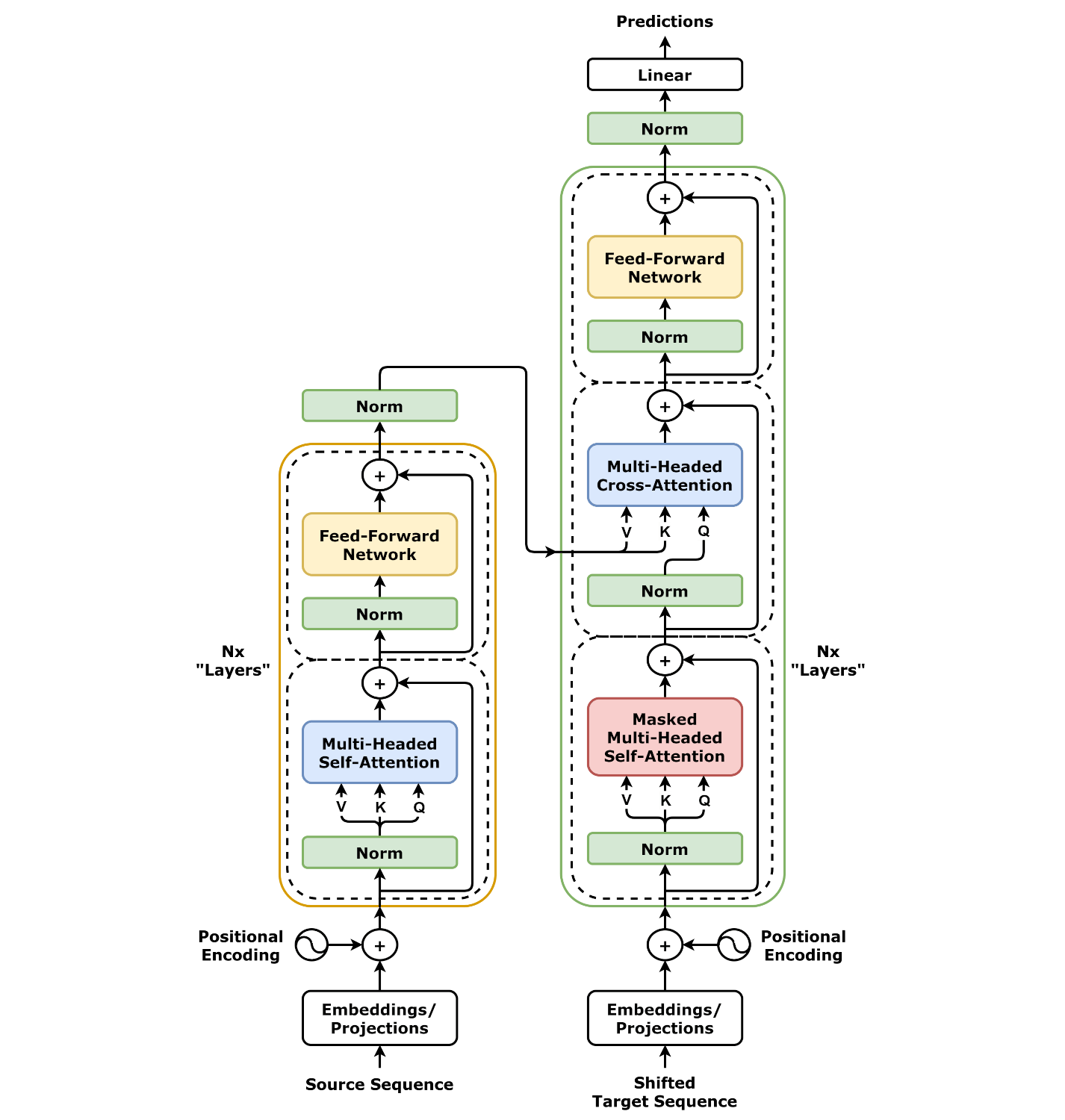{kind=link}