
 4 months ago
38
4 months ago
38
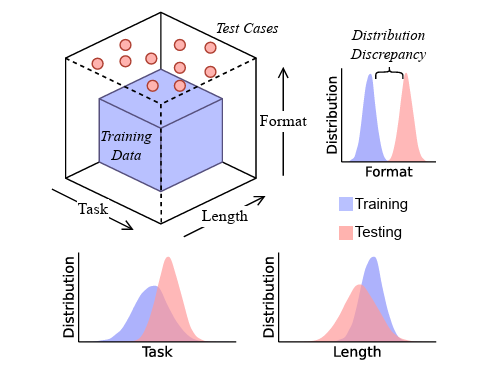
The researchers used test cases that fall outside of the LLM training data in task type, format, and length.
The researchers used test cases that fall outside of the LLM training data in task type, format, and length. Credit: Zhao et al
These simplified models were then tested using a variety of tasks, some of which precisely or closely matched the function patterns in the training data and others that required function compositions that were either partially or fully "out of domain" for the training data. For instance, a model trained on data showing two cyclical shifts might be asked to perform a novel transformation involving two ROT shifts (with basic training on what a single example of either shift looks like). The final answers and reasoning steps were compared to the desired answer using BLEU scores and Levenshtein Distance for an objective measure of their accuracy.
As the researchers hypothesized, these basic models started to fail catastrophically when asked to generalize novel sets of transformations that were not directly demonstrated in the training data. While the models would often try to generalize new logical rules based on similar patterns in the training data, this would quite often lead to the model laying out "correct reasoning paths, yet incorrect answer[s]." In other cases, the LLM would sometimes stumble onto correct answers paired with "unfaithful reasoning paths" that didn't follow logically.
"Rather than demonstrating a true understanding of text, CoT reasoning under task transformations appears to reflect a replication of patterns learned during training," the researchers write.
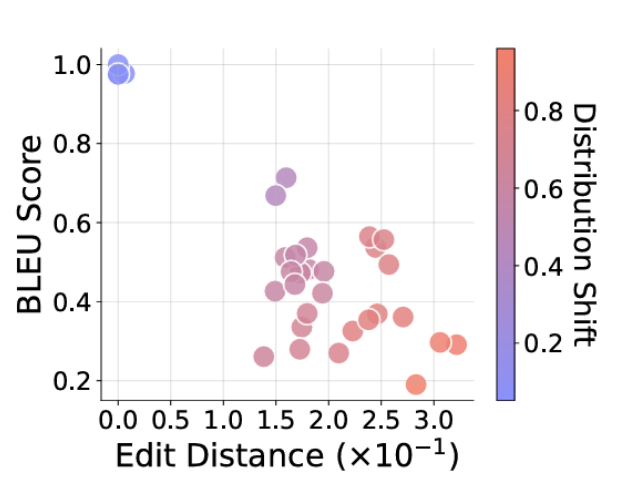
As requested tasks get further outside the training distribution (redder dots), the answers provided drift farther from the desired answer (lower right of the graph).
As requested tasks get further outside the training distribution (redder dots), the answers provided drift farther from the desired answer (lower right of the graph). Credit: Zhao et al
The researchers went on to test their controlled system using input text strings slightly shorter or longer than those found in the training data, or that required function chains of different lengths than those it was trained on. In both cases the accuracy of the results "deteriorates as the [length] discrepancy increases," thus "indicating the failure of generalization" in the models. Small, unfamiliar-to-the-model discrepancies in the format of the test tasks (e.g., the introduction of letters or symbols not found in the training data) also caused performance to "degrade sharply" and "affect[ed] the correctness" of the model's responses, the researchers found.








 English (US) ·
English (US) ·