
 2 weeks ago
8
2 weeks ago
8
This kind of variance—both within different GSM-Symbolic runs and compared to GSM8K results—is more than a little surprising since, as the researchers point out, "the overall reasoning steps needed to solve a question remain the same." The fact that such small changes lead to such variable results suggests to the researchers that these models are not doing any "formal" reasoning but are instead "attempt[ing] to perform a kind of in-distribution pattern-matching, aligning given questions and solution steps with similar ones seen in the training data."
Don’t get distracted
Still, the overall variance shown for the GSM-Symbolic tests was often relatively small in the grand scheme of things. OpenAI's ChatGPT-4o, for instance, dropped from 95.2 percent accuracy on GSM8K to a still-impressive 94.9 percent on GSM-Symbolic. That's a pretty high success rate using either benchmark, regardless of whether or not the model itself is using "formal" reasoning behind the scenes (though total accuracy for many models dropped precipitously when the researchers added just one or two additional logical steps to the problems).

An example showing how some models get mislead by irrelevant information added to the GSM8K benchmark suite.
An example showing how some models get mislead by irrelevant information added to the GSM8K benchmark suite. Credit: Apple Research
The tested LLMs fared much worse, though, when the Apple researchers modified the GSM-Symbolic benchmark by adding "seemingly relevant but ultimately inconsequential statements" to the questions. For this "GSM-NoOp" benchmark set (short for "no operation"), a question about how many kiwis someone picks across multiple days might be modified to include the incidental detail that "five of them [the kiwis] were a bit smaller than average."
Adding in these red herrings led to what the researchers termed "catastrophic performance drops" in accuracy compared to GSM8K, ranging from 17.5 percent to a whopping 65.7 percent, depending on the model tested. These massive drops in accuracy highlight the inherent limits in using simple "pattern matching" to "convert statements to operations without truly understanding their meaning," the researchers write.
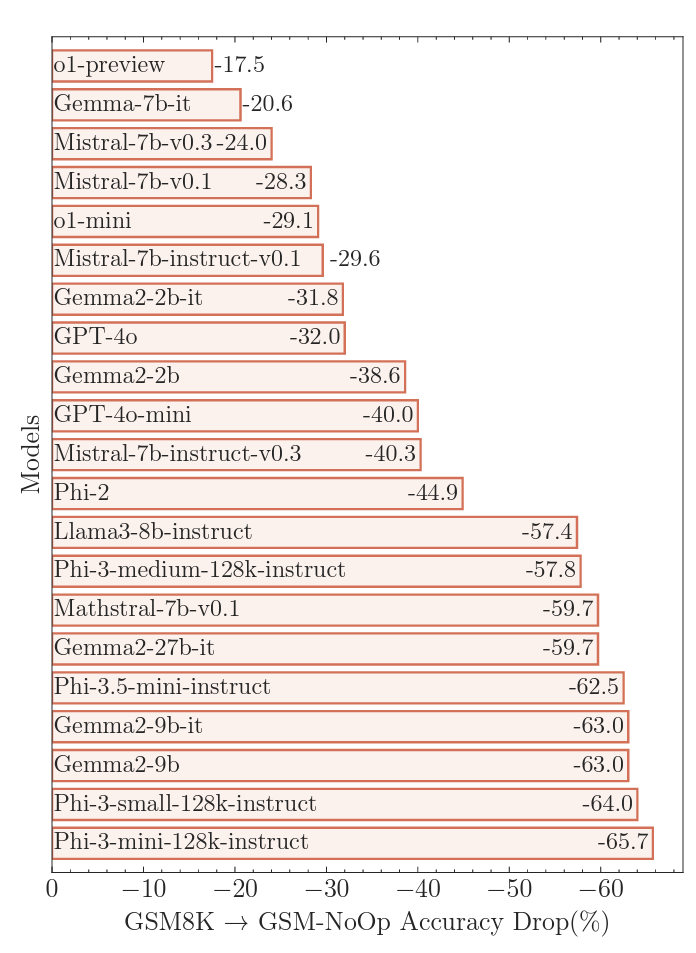
Introducing irrelevant information to the prompts often led to "catastrophic" failure for most "reasoning" LLMs
Introducing irrelevant information to the prompts often led to "catastrophic" failure for most "reasoning" LLMs Credit: Apple Research
In the example with the smaller kiwis, for instance, most models try to subtract the smaller fruits from the final total because, the researchers surmise, "their training datasets included similar examples that required conversion to subtraction operations." This is the kind of "critical flaw" that the researchers say "suggests deeper issues in [the models'] reasoning processes" that can't be helped with fine-tuning or other refinements.




:quality(85):upscale()/2023/09/21/802/n/1922729/d9a11ce9650c8850437280.00070284_.jpg)

:quality(85):upscale()/2024/10/30/955/n/42301552/28e49c1e6722ab5b973b38.46745005_.jpg)

 English (US) ·
English (US) ·